Firestore
Created: 2020-03-26 15:30:31 -0700 Modified: 2020-05-22 15:49:28 -0700
Cloud Firestore
Section titled “Cloud Firestore”- When creating the database, you can choose between Test Mode and Production Mode. Test Mode will make your database readable and writeable by anybody.
- The database itself has very fine-grained authorization rules (security rules, rule conditions), meaning you can expose the database directly to your clients if you want so that the server layer only has to concern itself with particular reads/writes. For example, a user may be able to see their own name and account age, but not their underlying IDs or number of logins. For writing data, it’s unlikely that you want to trust the client for anything without validation, but the database layer itself can do some basic validation.
- The big concern around allowing direct access to the database is if you ever mess up a security rule; you may grant more access than you want. The solution is thorough testing.
- Also, if you do grant users direct access, then you’ll probably want to listen for real-time updates directly on the client (reference).
- You store data in documents which are organized into collections. Collections contain nothing other than a set of documents, i.e. they can’t have metadata in them or other collections.
- Subcollections are collections that are children of documents. The hierarchy is always Collection → Document → Subcollection → Document → etc.; you cannot have a document or collection as a child of another document or collection respectively. You can nest up to 100 levels deep this way.
- If you try assigning data to a document that doesn’t exist, Cloud Firestore will create it.
- Similarly, a collection comes into existence as soon as a document is added to it. It is automatically deleted when the last document is removed.
- However, subcollections can still exist even if their parent path no longer exists (reference - read the warning at the bottom or see this SO post).
- Data types: boolean, number, string, geo point, binary blob, and timestamp. These can be organized into arrays/objects just like JSON.
- Documents are limited in size to 1 MB, so keep them small.
- While you’re not required to have consistency in fields or data types, it’s still advised to make filtering/sorting easier.
- The names of documents in a collection are unique. If you don’t provide your own IDs, then Cloud Firestore will assign random, unique values for you. Fields are indexed automatically, so I think the paradigmatic way of doing things is to just let Firestore assign the IDs for you. By doing this, you avoid hotspots too, but your data is less readable via listDocuments() alone.
- You can create references to any particular document or collection (reference).
- Writing/updating a document requires knowing its ID, so if your IDs are auto-generated, then you have to fetch and update in two queries (reference)
- Security (reference)
- The server client APIs have access to everything regardless of your Cloud Firestore Security Rules. However, you still need a security rule to prevent arbitrary users from getting access (e.g. a “deny all” rule).
- Local development
- There are two main routes: using the emulator (introductory reference, reference specifically for Cloud Firestore, reference for just arbitrary functions) and making a new database online intended solely for development purposes.
- Importing and exporting data
- There’s this StackOverflow post that I found that links to an official Google guide on it
- Best practices (reference)
- Don’t use monotonically increasing document IDs like user1, user2, user3 (reference)
- Generally try to avoid special characters in field names (other than hyphens or underscores). Basically just treat it like JavaScript when doing “obj.FIELD_NAME = value”.
- Indexes are made for you. The only thing you need to do is potentially exempt certain fields (like large strings, large maps) from indexes to improve performance (reference)
- Don’t write many small updates to the same document; batch them instead (reference).
Security rules
Section titled “Security rules”Basics
Section titled “Basics”- You cannot control the security of individual fields in a document; it’s all-or-nothing (reference).
- The emulator reads from a file named firestore.rules (reference).
- Syntax guide here
- Examples (more here)
- Compare a type: request.resource.data.blurb is string
- Examples (more here)
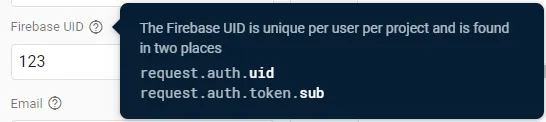
- “request.auth.token” can contain “email”, “email_verified”, “phone_number”, “name”, and “sub”, where “sub” is the user’s UID (the Rules Playground itself says this):
- “request.resource” maps to what the final resource would look like if a write/update were to succeed, so you can test its data to validate input:
- Examples
- Ensure client-specified data matches a “schema”: request.resource.data.keys().hasOnly([‘name’, ‘age’]) && request.resource.data.name is string && request.resource.data.name.size() > 5 && […validations on age]
- Note: you’d almost certainly want to make functions for these checks
- Validate a field only if it exists (reference):
- Ensure client-specified data matches a “schema”: request.resource.data.keys().hasOnly([‘name’, ‘age’]) && request.resource.data.name is string && request.resource.data.name.size() > 5 && […validations on age]
- Examples
function isLastNameValid() { return request.resource.data.last_name == null || request.resource.data.last_name.size() > 2;}- Their built-in “Rules playground” in the console is great (reference):
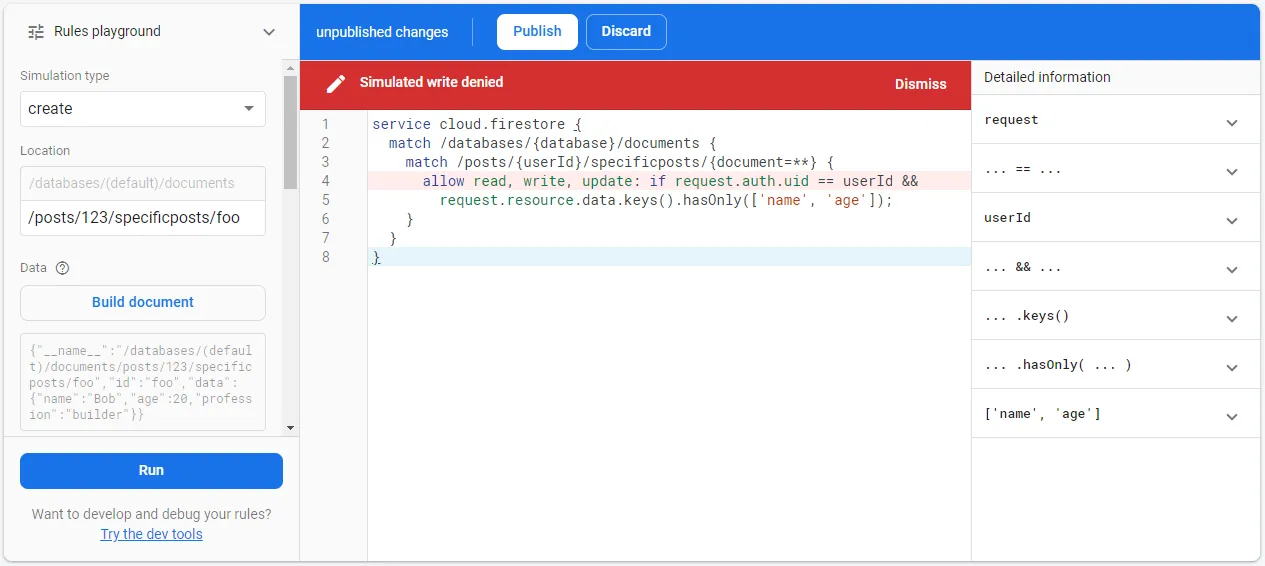
- The right side shows you all of the conditions/values (although you need to expand them) so that you can see exactly what prevented a read/write.
Examples
Section titled “Examples”Quick example of how to lock down the whole database except for a single subcollection
Section titled “Quick example of how to lock down the whole database except for a single subcollection”In this example, I have a “reviews” collection with documents representing each course (e.g. “FIREBASE”, “CALCULUS”), and I want every user to be able to directly read those documents:
rules_version = '2';service cloud.firestore { match /databases/{database}/documents { match /{document=**} { allow read, write: if false; }
match /reviews/{courseId}/reviews/{document=**} { allow read: if true; } }}- Allowed
- GET /reviews/FIREBASE/reviews/12h5k1h5jk1h5jkb
- GET /reviews/CALCULUS/reviews/ewhjkthjetkwhjtek
- Not allowed
- WRITE /reviews/FIREBASE/reviews/12h5k1h5jk1h5jkb
- GET /reviews/FIREBASE
General structure
Section titled “General structure”This example just shows some general structure, data validation, etc. It’s meant to be a quick reference.
service cloud.firestore { match /databases/{database}/documents { match /posts/{document=**} { allow read: if true; } match /posts/{userId}/specificposts/{document=**} {
function hasOnlyAllowedKeys() { return request.resource.data.keys().hasOnly(['body', 'author', 'timestamp']); }
function isBodyValid() { return request.resource.data.body is string && request.resource.data.body.size() > 0 && request.resource.data.body.size() < 100; }
function isOwner() { return request.auth.uid == userId; }
function didSpecifyDisplayName() { return request.auth.token.name == request.resource.data.author; }
function isTimestampValid() { return request.resource.data.timestamp is timestamp && request.resource.data.timestamp == request.time;
}
allow write, update: if isOwner() && hasOnlyAllowedKeys() && isBodyValid() && isTimestampValid() && didSpecifyDisplayName(); } }}Pseudo-migration
Section titled “Pseudo-migration”⚠BACK UP THE DATABASE BEFORE YOU DO THIS⚠
Suppose you want to get all of your registered users and update them in Firestore (sort of like a migration might do in a SQL database). I adapted some code from here to do this. My code below will inject “lastKnownEmail” into each user’s document based on what Firebase Auth knows about them:
const admin = require('firebase-admin');const _ = require('lodash');
admin.initializeApp({ credential: admin.credential.applicationDefault(),});
const db = admin.firestore();const usersRef = db.collection('users');
async function processAllUsers(nextPageToken) { try { const listUsersResult = await admin.auth().listUsers(1000, nextPageToken); const { users: userRecords } = listUsersResult; console.log(`Fetched ${userRecords.length} user(s)`); for (let i = 0; i < userRecords.length; ++i) { const { uid, email, displayName } = userRecords[i];
const querySnapshot = await usersRef.where('uid', '==', uid).get(); if (querySnapshot.empty) { // This could happen if the account got deleted since we enumerated the // users. console.error(`User not found for uid=${uid} - skipping`); continue; }
console.log(`Updating ${displayName} → ${email}`); const usersDocument = _.head(querySnapshot.docs); await usersDocument.ref.update({ lastKnownEmail: email, }); }
if (listUsersResult.pageToken) { // List next batch of users. console.log('Getting next page of users'); await processAllUsers(listUsersResult.pageToken); } } catch (error) { console.log('Error listing users:', error); }}
processAllUsers().then(() => { console.log('Done'); process.exit(0);});NodeJS
Section titled “NodeJS”Basics
Section titled “Basics”- If you’re returning data to users, always call “.data()“. For example, if you have code like this:
const firstDoc = _.head(querySnapshot.docs); return firstDoc; // notice: .data() is missing - this is badThis will return a lot of metadata from the server, including your service account’s credentials. If a client has this, then they can read/write your whole database. Here’s a snippet from the response when I had the code above:
{ "result": { "_fieldsProto": { // stuff the user probably should have access to }, "_ref": { "_firestore": { "_settings": { "credentials": { "private_key": "-----BEGIN PRIVATE KEY-----redactedn-----END PRIVATE KEY-----n", "client_email": "redacted" },I assume that this isn’t such a big deal for most people because it’s paradigmatic of Firestore to allow users direct access to collections and documents as long as they’re locked down with proper security rules, so I don’t think many people are making Functions to access data from Firestore when a user could just do that by themselves. Still, here’s an issue where people are talking about it, and here’s a StackOverflow post where people talk about it.
- Dates can be accessed via admin.firestore.FieldValue.serverTimestamp() or admin.firestore.Timestamp.now() (comparison here on StackOverflow). Also note: on the client, it’s firebase.firestore.FieldValue.serverTimestamp().
- If you give clients direct access to the database, then your security rules need to validate that an expected timestamp of “now” is always actually now (reference)—your security rule must check “if request.resource.data.timestamp == request.time”.
- To get a JavaScript Date object out of a timestamp, use .toDate() (reference)
const timestamp = new firebase.firestore.Timestamp( result.data.createdAt._seconds, result.data.createdAt._nanoseconds ); timestamp.toDate();Getting started on local NodeJS (NodeJS API docs here)
Section titled “Getting started on local NodeJS (NodeJS API docs here)”- I’m following the quick-start guide here. The goal is to just interact with a database to see how it works.
- When creating a database, I set the security to Production Mode.
- I needed to make a service account to give access to my computer. UPDATE: apparently one is created for your by default called firebase-adminsdk. There’s a special section called “Service accounts” in the settings where you can click “Generate new private key”, but this does not revoke the old private key. For that, you have to click the link at the left side to get to the underlying service account, edit, and then delete the key.
- This was on Google Cloud Platform at this point, a page like this: https://console.cloud.google.com/iam-admin/serviceaccounts/create?authuser=0&project=learning-firebase-8f44e
- I clicked “Create service account”, named it “my-computer”.
- For roles, I just made the account a Project Owner so that it gets access to everything. In the future, it’d be a good idea to cut down those roles to contain breaches.
- After that, I copy/pasted the code that they show in the guide, and I was able to set some data. This data then became visible in the Firebase Console → Database → Data. There’s a quick link to this data here after you choose your project.
Here’s some simple code that I ended up with that will add two users every time you run it (even if they already exist) and fetch users (potentially multiple) based on the name:
async function test() { const usersRef = db.collection("users"); let docRef = db.collection("users").doc("adam"); await usersRef.add({ first: "Bob", stuffAboutBob: "it's here" }); await usersRef.add({ first: "Alice" });
const querySnapshot = await usersRef.where("first", "==", "Bob").get(); querySnapshot.forEach(documentSnapshot => { console.log( `Found document at ${documentSnapshot.ref.path}: ${JSON.stringify( documentSnapshot.data() )}` ); });}
test().then(() => { console.log("Success");});Transactions (reference, API docs)
Section titled “Transactions (reference, API docs)”Basics
Section titled “Basics”- Only “get” and “getAll” are asynchronous.
- Transactions don’t even have functions to get references, so it’s safe to use something like admin.firestore().collection(“users”) in your transaction.
- Creating a document requires a reference. If you want a document with an auto-generated ID, just use .doc() on a CollectionReference.
Troubleshooting
Section titled “Troubleshooting”Uncaught (in promise) FirebaseError: false for ‘list’ @ L5
This is a generic permissions issue. If you’re running locally or in development, you can confirm this by changing your security rules to these that give all permissions to everyone (i.e. very dangerous to put in production):
rules_version = '2';service cloud.firestore { match /databases/{database}/documents { match /{document=**} { allow read, write: if true; } }}If that does indeed fix things, then you’ll need to figure out which rule you messed up. In my case, I’d accidentally typed a rule as “match /reviews/{document=}/reviews” instead of “match /reviews/{courseId}/reviews/{document=}”, but it could be literally anything.