Rust (rustlang)
Created: 2020-06-15 08:42:33 -0700 Modified: 2022-12-18 19:38:58 -0800
Notes to self
Section titled “Notes to self”(these are specifically for myself later)
- Relearning Rust in late 2022 - where I left off
- Book: https://doc.rust-lang.org/stable/book/ch08-01-vectors.html
- Rustlings: I made it to iterators2.rs. See info.toml for the order of the exercises.
- I wanted to read https://rust-lang.github.io/api-guidelines/
- I wanted to enable all possible Clippy warnings once I started writing “real” Rust
- Quick links
- API documentation for the standard library
- Rust by Example: official resource with lots of practical examples for many topics
- Rust Cheat Sheet - very similar to Rust by Example, but the examples are very small
- Compiler error index (e.g. for searching “E0308”, although you can also do “rustc —explain E0308”)
- The Rustonomicon: all of the arcane details of Rust
- Playground - easily test/share code, sort of like a pastebin. You can also use this to view the assembly output (three dots → “ASM”)
- https://blessed.rs/ - opinionated “best” choices so that you don’t have to wade through crates.io
- Rustlings: a guided set of exercises to help you learn. Starts out very easy. IMO, it’s helpful to run “hint” from the “rustlings watch” command after solving an exercise to make sure you did the right thing.
- Rhymu’s playlist on learning Rust: it’s like a video guide through the Rust book!
- They have three different paths for getting started that are listed here. There are web-dev and game-dev guides as well.
- I went through the book, and chapters took an average of about 75 minutes or so while streaming (meaning I was distracted). Chapter 10 was beefy and took about 3 hours.
- Qualities of the language
- The language itself is open-source. In the documentation, you can click the “[src]” button on the side to see how it’s implemented.
- Static typing (all types must be known at compile time) (reference)
- It’s expression-based (reference).
- Statement: instructions that perform an action but don’t return a value, e.g. “let x = 6;“. However, “let x = y = 6;” or “let x = (let y = 6);” are both invalid.
- Expression: instructions that evaluate to a resulting value, e.g. “x + 2” (with no semicolon, or it would become a statement).
- There is no garbage collector. Instead, each value in Rust has an owner. See the “ownership” section.
- Like with Golang (reference), there’s automatic referencing and dereferencing with the ”.” operator (e.g. for methods), meaning you don’t need ”->” like you would in C/C++ (reference). You still need to manually dereference for cases like modifying a mutable vector while iterating over it (reference) (the code is “*i += 50;” in that example).
- Rust puts bug-prevention at the top of its priorities. Examples:
- Buffer overruns cause panics rather than undefined behavior (https://doc.rust-lang.org/book/ch09-01-unrecoverable-errors-with-panic.html#using-a-panic-backtrace)
- Rust uses snake_case for variables and function names.
- To turn off particular warnings, you use this syntax (not in a comment):
#[allow(dead_code)]- Visual Studio Code extension here (other IDE extensions here)
- Automatically formatting code
- Rust comes with rustfmt (which should be in your PATH after installing rustup), but the extension can’t use this without the Rust Language Server (RLS) running. To install that (reference):
- Automatically formatting code
rustup component add rls rust-analysis rust-src-
After installing the extension, RLS, and its dependencies, restart VSCode. After that, if you get an error about “There is no formatter for ‘rust’ files installed”, then it means that your file has to be inside of a workspace (reference).
- Also, if features in VSCode don’t seem like they’re working, then you may have to trust the workspace that you’re running in (“Manage Workspace Trust” in the command palette).
- The “Quick Fix…” action (ctrl+. by default) will help a lot for autofilling things like structs.
-
If you ever want to run this from the command line, you can just run “rustfmt file.rs”.
-
Refactoring
- You can right-click code → Refactor → Extract into function
-
Other IDE-like functionality
- You can find most of this behavior (like “Find All References”) by simply right-clicking a symbol in your code. There’s lots of useful stuff!
- Other useful things:
- Debug just by clicking “Debug” over your main function.
-
Other interesting settings
- Rust-analyzer → Inlay Hints → Lifetime Elision Hints: Enable
- This is helpful when learning lifetimes. Here’s an example of what it does.
- “rust-analyzer.checkOnSave.command”: “clippy”
- This’ll automatically run Clippy every time you save, and it’ll highlight linter errors in red directly in the editor. See all Clippy checks here.
- Rust-analyzer → Inlay Hints → Lifetime Elision Hints: Enable
-
Their package-managing site is called crates.io
- Each crate has a license and potentially a link to its repository
- To install a crate, you typically go to its page, click either of the buttons below depending on which page you’re on, and then paste into Cargo.toml

- There are two major command-line tools:
- rustup - this helps manage Rust’s version and associated tools
- cargo - this is for everything else - the build system, installing packages, running code, etc.
- Rust automatically injects its standard library, the prelude, into each crate (reference)
Language
Section titled “Language”-
Miscellaneous
- Rust refers to “static” properties or methods as “associated”
-
Packages, crates, and modules (reference)
-
Terminology (reference)
-
Package: a Cargo feature that lets you build, test, and share crates. There can only be one library crate per package (reference).
- Packages contain a Cargo.toml file.
- Packages must contain at least one crate.
-
Crates: a tree of modules that produces a library or executable (called “library crates” and “binary crates”)
- Binary crates always have main.rs, library crates always have lib.rs
-
Modules: let you control the organization, scope, and privacy of paths (e.g. with public vs. private).
- Modules are defined with the “mod” keyword.
- Modules can be nested.
- Modules are sort of like namespaces.
-
Paths: a way of naming an item (like a struct, function, or module). The “use” keyword lets you bring a path into scope.
-
Workspaces exist to allow for monorepos sort of like LernaJS in JavaScript. They share one Cargo.lock file and output directory.
-
-
All items in a module are private by default and require the “pub” keyword to make them public (reference).
- If you have a public module within a private module, then only the public module’s ancestors can refer to it.
- A struct can be made public without making its fields public. Private fields can neither be read nor written.
-
With modules, you can use “super” to refer to the parent module (reference), e.g. super::some_function().
-
Paths that refer to an item in the module tree can either be absolute or relative (reference).
-
The “use” directive
- You don’t always have to use a “use” directive (reference, reference2).
-
// With "use"use std::ioio::stdin().read_line(&mut guess);
// Without "use"std::io::stdin().read_line(&mut guess);- They talk about idiomatic “use” usage here - they generally say to “use” up to the final module when it comes to functions, not right up to the function itself, that way your final call will look like “hosting::eat_food()” instead of just “eat_food()“. However, with structs, enums, and anything else that’s not a function, path directly up to the type.
- If you want to alias names with “use”, use “as” (reference)
- You can re-export names with “pub use” (reference)
- You can nest paths with curly braces (reference):
// These two lines can be consolidated into the line belowuse std::cmp::Ordering;use std::io;
// (consolidated)use std::{cmp::Ordering, io};- Splitting code into different files (reference). Here’s an example:
pub mod hosting { pub fn add_to_waitlist() {}}
// src/lib.rsmod front_of_house;
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() { hosting::add_to_waitlist(); hosting::add_to_waitlist(); hosting::add_to_waitlist();}-
The convention is for your binary crate to be a very thin wrapper around your library crate, that way testing can be facilitated (reference). The reason why is that binary crates can’t be used by other crates, including tests, and integration tests require being in a “tests” directory outside of the scope of your crate.
- Here are some guidelines around how to make your first couple of files, main.rs and lib.rs (reference)
-
String formatting
- Basic formatting is done with curly braces:
println!("x = {}, y = {}", x, y);- You can “sprintf” via the format macro:
.expect(format!("You needed a number but typed {}", value));- You can print the debug format of anything that implements Debug by using {:?} (or its “pretty” version, {:#?} )as a formatter, e.g.
println!("Value: {:?}", some_value);For strings, this will print any “hidden” characters like “rn”.
- Alternatively, you may find it easier to use the dbg! macro, e.g.
dbg!(some_value);- This has a special property of allowing you to “pass through” the data (dbg! will take ownership of your value and return it) (reference):
The expression
2 + 3 * 4…can be rewritten as
2 + dbg!(3 * 4)-
When you want to maintain ownership of something, you woud either need to capture dbg!‘s output:
- user = dbg!(user);
- …or simply use a reference:
- dbg!(&user);
-
Mutable function argument example (reference)
- I’m putting this syntax example here just because I think it’ll come up later, but it’s covered in more depth by other sections in this note.
fn main() { let mut s = String::from("hello");
change(&mut s);}
fn change(some_string: &mut String) { some_string.push_str(", world");}This shows how you use all of the ”&” and “mut” instances.
- Match (reference)
- This is like a “switch case” in other languages, but it doesn’t require explicit “break” statements. The important part for Rust is that Rust ensures that you’ve got a code-path for every potential branch (i.e. it’s exhaustive).
- Cases are called “arms” (reference).
- Sample syntax:
enum Coin { Penny, Nickel, Dime, Quarter,}
fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, }}- You can match on any type, not just an integer or string.
- When matching on types, you can extract data from the type with pattern matching (reference). This is shown below with the Coin::Quarter case:
enum UsState { Alabama, Alaska, // …more states}
enum Coin { Penny, Nickel, Dime, Quarter(UsState),}fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10,
// In the line below, we'll bind the variable "state" to the UsState that the Coin::Quarter holds Coin::Quarter(state) => { println!("State quarter from {:?}!", state); 25 } }}- Using ”_” or any variable name, you can match only some values if you want, e.g. you have a u8 but you only want to test for values 1,3,5,7 (reference):
let some_u8_value = 0u8;match some_u8_value { 1 => println!("one"), 3 => println!("three"), 5 => println!("five"), 7 => println!("seven"), _ => (), // we're explicitly saying that we're not going to exhaustively check every other number. Also, "()" is the unit value, so nothing will happen in this case.}-
Use the ”_” when you don’t want to bind the value to a variable, and use a name when you actually need to use the value.
-
If you only care about one specific pattern and don’t need exhaustive checks, then use the “if let” construct instead of a match (reference)
let some_u8_value = Some(0u8);if let Some(3) = some_u8_value { println!("three");}-
It’s worth remembering that the “Some” goes on the left to get the value out of an option.
-
This still uses the pattern-matching logic of “match” under the hood, meaning something like this is fine: if let Coin::Quarter(usState) = coin { /code involving “usState”/ }
-
If you include an “else”, then it’s just like the ”_” case of “match”.
-
You can use comparison operators in a match like this:
let value = -1;
match value { x if x < 0 => println!("Negative"), x if x == 0 => println!("Zero"), _ => println!("Positive"), }-
I checked it out on the Rust playground and it seems to generate assembly code as though “if” statements were used, so this can be a good way to make readable arms.
-
Matches can sometimes be removed by using unwrap_or_else combined with closures (as mentioned in chapter 9, although it refers to chapter 13).
-
Enumerations (reference)
- Just like in other languages, an enum is a way of saying that a value is one of a possible set of values. Enums can hold data just like structs can (they can even hold structs themselves or other enums). Determining when to use a struct vs. an enum is covered a bit on this page.
- An enumeration’s values are called its variants, and saying something like “four = IpAddrKind::V4” is instantiating a variant.
- Sample syntax:
// Define an enumerationenum IpAddrKind { V4, V6,}
fn main() { // Create an instance of the V4 variant let four = IpAddrKind::V4;
route(IpAddrKind::V4);}
fn route(ip_kind: IpAddrKind) {}- You can also put data about a variant directly into the variant itself (reference)
enum IpAddr { V4(u8, u8, u8, u8), V6(String),}let home = IpAddr::V4(127, 0, 0, 1);let loopback = IpAddr::V6(String::from("::1"));- Regarding when to make an enum variant contain data directly, the docs mention this (reference):
But if we used the different structs, which each have their own type, we couldn’t as easily define a function to take any of these kinds of messages as we could with theMessageenum defined in Listing 6-2, which is a single type.
- IP-address code is baked right into the standard library, and they used structs inside the enum variants so that the code looks like this:
struct Ipv4Addr { // ...code...}
enum IpAddr { V4(Ipv4Addr), V6(Ipv6Addr),}- Just like with structs, we can define methods directly in an enum (reference):
enum Message { // …code…}impl Message { fn call(&self) { // method body would be defined here }}- The Option enum (reference, API docs)
- This is an enum defined by the standard library to handle the option for a value to be nothing since Rust has no concept of null.
- On a related note to not having null, whenever you see “let x;” with no instantiation, it’s not actually set to null. Attempting to use it would result in a compile-time error. This is clarified in the first note of this section of the book.
- The definition of Option is as follows:
- This is an enum defined by the standard library to handle the option for a value to be nothing since Rust has no concept of null.
enum Option<T> { Some(T), None,}-
By being part of the prelude, you can use Some and None without needing to explicitly bring them into scope, meaning you only really have to type “Option” if you’re using “None” since the compiler can’t infer the type from “None” on its own, e.g. let absent_number: Option<i32> = None;
-
The most idiomatic way of using the value is to employ “match” to test both cases. You must test both cases or else the program may panic (the API docs show that there’s “unwrap” and “expect”, both of which will give you a value but panic if the value is None). Example below (reference):
fn plus_one(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), }}- Variables and mutability (reference)
- “let” implies something is a variable, and it’s constant by default unless you add “mut” after it, indicating that it’s mutable. Rust has const-by-default for safety and easy concurrency (reference).
- Technically, “let” is binding a value to a variable. You can actually redefine the binding.
- Rust does have a “const” keyword (reference).
- Consts are FULLY_CAPITALIZED (although if they aren’t, it’s just a warning, not an error).
- Consts must include a type rather than inferring the type.
- Consts can be declared in the global scope, whereas “let” cannot be.
- Consts can only be set to constant expressions, not the result of a function call
- Shadowing (reference)
- You can shadow variables (not constants) by rebinding the value in a “let” statement. This also lets you change the type of the shadowed variable (reference).
- You can shadow immutable variables (e.g. by just saying “let x = 5;” twice). This allows you to perform transformations on a value but have the final variable be immutable.
- Since we’re technically creating a new variable, this lets us change the type of a variable. That’s something you wouldn’t be able to do just with “let mut”.
- This is nice so that you don’t need something like “message” and “message_length”; you could just reuse the same variable.
- Data types (reference)
- There are scalar types and compound types.
- Scalars are integers, floating-point numbers, booleans, and characters.
- Integers
- Integers default to i32 (reference).
- Integers have isize and usize for signed/unsigned values based on your computer architecture (32- or 64-bit).
- Integers can use underscores as visual separators, e.g. 1_000_000 to represent a million.
- When compiling without the “—release” flag, you’ll have runtime integer-overflow checks performed automatically.
- Floating-point numbers default to f64 (reference)
- Character literals use single quotes. Characters are Unicode scalar values, so they’re 4 bytes in size.
- Note that std::string::String does not store characters the same way (reference):
- Integers
- Scalars are integers, floating-point numbers, booleans, and characters.
- There are scalar types and compound types.
- “let” implies something is a variable, and it’s constant by default unless you add “mut” after it, indicating that it’s mutable. Rust has const-by-default for safety and easy concurrency (reference).
[11:49] ectonDev: Strings are stored as encoded UTF-8 strings in a u8 buffer, and when you ask for chars you get it decoded in a safe manner into unicode code points
[11:50] ectonDev: Basically you can ask a String for bytes or you can ask for chars, but you have to pick one
- Compound types are tuples and array (reference)
- Tuples (reference)
- Tuples can have a variety of types in them.
- ”()” is a tuple without any values and has a special name, “unit”.
- Syntax example:
- Tuples (reference)
// Define a tuplelet tup: (i32, f64, u8) = (500, 6.4, 1);
// Destructure a tuplelet (x, y, z) = tup;
// Alternative creation/access via individual members let x: (i32, f64, u8) = (500, 6.4, 1); let five_hundred = x.0; let six_point_four = x.1; let one = x.2;- Arrays (reference)
- Every array element must have the same type
- Arrays have a fixed length (unlike vectors)
- Arrays are allocated on the stack rather than the heap
- Syntax example:
// Define an array
let a = [1, 2, 3, 4, 5];
// Define an array with a specific type/count
let a: [i32; 5] = [1, 2, 3, 4, 5];
// Define an array with the same value repeated 5 times
let a = [3; 5]; // equivalent to [3,3,3,3,3]
// Access
let first = a[0];
- Type inference can work based on where we’re attempting to store a result. For example, you can parse a string as many different types, but in the code below, we know we want a u32, so .parse() will return a u32 (reference):
let guess: u32 = "42".parse().expect("Not a number!");You can also use the turbofish operator (::<>) for this:
let guess = "42".parse::<u32>().expect("Not a number!");- References (with ”&”) are immutable by default, so if you’re passing a reference that needs to be mutable, specify “mut” before it:
std::io::stdin().read_line(&mut guess);- Macros (reference)
- Macros are called with an exclamation point between the macro name and the parentheses. The most common one is println: println!(“Hello world”)
- Here’s a good StackOverflow explanation of why println is a macro and not a function.
- You can see the expanded macro code by installing cargo-expand.
- Macros are called with an exclamation point between the macro name and the parentheses. The most common one is println: println!(“Hello world”)
- Functions (reference)
- You must annotate each parameter with a type (reference).
- Flow for making a function signature:
- Parameters
- Are you modifying the parameter? If so, add “mut” to it.
- Do you want borrow ownership of the parameter? If so, add ”&” to it. If not, omit the ”&” and the function you’re defining will claim ownership of the parameter.
- Parameters
- Sample syntax:
fn plus_one(x: i32) -> i32 { // return value comes after an arrow x + 1 // this is an expression (see below) that will just return x+1}- Expressions don’t have a semicolon on them (reference), e.g.
let y = { let x = 3; x + 1 // This line has no semicolon, so it's returning the value 4};-
Originally, I was thinking that not requiring an explicit “return” statement was unusual from Rust since they want to enforce safety everywhere, but if you were to accidentally add a semicolon to a return expression, it would become a statement instead, which would violate the signature of the function (see the bottom of this section for more details).
- Note that there is a “return” keyword, but it’s only for early returns. This is exemplified by listing 9-6 (reference). There, you can see that there’s an expression in a “match” and also a “return”.
-
You can’t return multiple values from a function, so if you want that same behavior, return a tuple instead. Here’s syntax of a contrived example:
fn get_property() -> (String, bool) { let name = String::from("visible"); (name, true)}- “if” expressions (reference)
- Requirements
- Conditions have to be bool (as opposed to something like C or JavaScript where there’s false-y and truthy)
- Bodies need curly braces
- Just like with “match” expressions, the blocks of code associated with “if” expressions are called “arms”.
- Sample syntax
- Requirements
if number < 5 { // code } else if number > 7 { // code } else { // code }- Because “if” is an expression, you can use it in assignments like so (reference):
let number = if condition { 5 } else { 6 };- Loops (reference)
loop { println!("again!"); // You can use "break;" here or even "break EXPRESSION;"}
// This shows how you can use loop as an expressionlet result = loop { counter += 1;if counter == 10 { break counter * 2; }};- while (reference)
while number != 0 { println!("{}!", number);
number -= 1;}- for (reference)
- This is just used for iterating over collections (as opposed to something like “for i = 0, i < 10; i++”).
- Sample syntax
let a = [10, 20, 30, 40, 50];
for element in a.iter() { println!("the value is: {}", element); }- If you do want to iterate over a set of numbers, they still have to be a collection, which in this case would be a Range:
for number in 1..4 { println!("{}!", number);}↑ That prints “1!”, “2!”, and “3!” on separate lines. To get “4!” to print out, put an equals sign in the range:
for number in 1..=4 {- The iterators returned by “iter()” have an “enumerate” method that works like how Python’s does where it returns a tuple of the element pointed at by the iterator alongside its numerical index.
fn first_word(s: &String) -> usize { let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } }
s.len()}-
This also shows off destructuring right in the “for” loop
-
Iterators themselves are always mutable, otherwise “.next()” wouldn’t work. This does not mean that what they point to is mutable.
-
[Memory] ownership (reference)
- TL;DR: Rust doesn’t use a garbage collector and also doesn’t explicitly require calls to allocate or free memory. Instead, there’s a concept of ownership. In short, each variable has exactly one owner, and when the owner goes out of scope, the variable is freed automatically.
- This pattern is similar to C++‘s “resource acquisition is initialization” (RAII). In C++, you have a constructor and a destructor, but that’s bound to a scope.
- The reference link has a nice little explanation of stack vs. heap and why each one exists. In short:
- The stack is for values whose number of bytes required to store them are known at compile time. The stack is fast. The stack is last-in-first-out.
- The heap is for values whose number of bytes required to store them are unknown at compile time.
- There are three rules of ownership:
- Each value in Rust has a variable that’s called the owner
- There can only be one owner at a time
- When the owner goes out of scope, the value will be dropped
- Rust has an internal “drop” trait that apparently you practically never have to manually call. This is similar to “free” or “delete” in C/C++.
- Move (vs. shallow copy or deep copy) (reference):
- TL;DR: Rust doesn’t use a garbage collector and also doesn’t explicitly require calls to allocate or free memory. Instead, there’s a concept of ownership. In short, each variable has exactly one owner, and when the owner goes out of scope, the variable is freed automatically.
fn main() { let s1 = String::from("hello"); let s2 = s1; // s1 is moved into s2}-
At this point, s1 is no longer a valid reference. This is done to avoid double-freeing the underlying string when s1 and s2 go out of scope.
-
Clone (reference)
- When you explicitly want to deep-copy some data, you can use “clone”. Rust’s copies outside of clone, by default, will always be inexpensive shallow copies (e.g. with integers) or moves (e.g. with the code shown above).
- Copy and Drop traits (reference)
- In short, what I think this section is trying to say is:
- All primitive types (integers, bool, etc.) are Copy (note: this terminology of “are Copy” or “is Copy” is not a typo; the docs say that), meaning that when you do something like the code below, the underlying values will be copied on the stack:
- In short, what I think this section is trying to say is:
fn main() { let x = 5; let y = x;}-
Any combinations of primitive types (e.g. a tuple of three integers) is also Copy.
-
Anything that is Drop cannot be Copy since Drop implies that memory was allocated on the heap. The reason why a type can’t be Copy and Drop is because Copy implies that the underlying data is on the stack, so we already know what to do when the owner goes out of scope, which is to pop it from the stack. However, Drop indicates that something more has to be done when the owner goes out of scope, which isn’t the case.
-
Ownership with respect to functions (reference)
- Ownership can be transferred in ways that are non-obvious to a new Rust programmer. Look at the following code (farther down in these notes, I refer to this example again):
let greeting = String::from("hello");dbg!(greeting);println!("{:#?}", greeting); // error: value borrowed here after move- Ownership can also be transferred by return values (reference). This example from the reference link combines everything to show how you may “fix” the “dbg!” code above:
fn main() { let s1 = gives_ownership(); // gives_ownership moves its return // value into s1
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2 is moved into // takes_and_gives_back, which also // moves its return value into s3} // Here, s3 goes out of scope and is dropped. s2 goes out of scope but was // moved, so nothing happens. s1 goes out of scope and is dropped.
fn gives_ownership() -> String { // gives_ownership will move its // return value into the function // that calls it
let some_string = String::from("hello"); // some_string comes into scope
some_string // some_string is returned and // moves out to the calling // function}
// takes_and_gives_back will take a String and return onefn takes_and_gives_back(a_string: String) -> String { // a_string comes into // scope
a_string // a_string is returned and moves out to the calling function}- As we can see from the example above, in order to take and give back ownership, we just have to return the variable so that the original caller can reclaim ownership. Thus, in my example where I had a borrow error, I could have either shadowed the original “greeting” variable or made it mutable:
fn main() { let greeting = String::from("hello"); let greeting = dbg!(greeting); println!("{:#?}", greeting); // no longer an error}- Ownership and scope have an important distinction. Consider this code:
fn gives_ownership() -> String { let some_string = String::from("hello"); some_string}-
“some_string” goes out of scope at the end of gives_ownership, but the ownership of the underlying String can be transferred to the caller (as long as the caller uses the return value).
-
This concept of explicitly returning everything just for the sake of ownership can be simplified with references (which Rust calls “borrowing”) (reference), e.g.
// This does NOT take ownership of "s" since the type is a reference.// We say that we've "borrowed" sfn calculate_length(s: &String) -> usize { s.len()}- Just like other languages with ”&” as the reference operator, ”*” is the *dereference* operator.
- References are immutable by default unless “mut” is specified in both the argument and the parameter (reference). If you have a mutable reference, then no other references (not even immutable ones) to that value can exist simultaneously (reference). This is disallowed:
let mut s = String::from("hello");
let r1 = &mut s;let r2 = &mut s;-
This is to prevent data races (which is considered by most to be a subset of a race condition). Picture if two threads could each have a mutable reference to some variable and they try to modify that data at the same time without any kind of synchronization—they both might read the value and then perform their write, meaning one might stomp on the other.
-
You also can’t have both immutable references and mutable references to a piece of data in a particular scope (because the user of an immutable reference wouldn’t expect it to suddenly change) (reference).
-
Macros can do some unusual things to bypass taking ownership (reference). For example, println! does not take ownership of values and also doesn’t require callers to include an ”&” in their arguments.
-
Dangling references (reference)
- The compiler guarantees that you’ll never have a pointer to “invalid” data (i.e. a pointer that has been freed already). This code will not compile:
fn main() { let reference_to_nothing = dangle();}
fn dangle() -> &String { let s = String::from("hello"); // "s" is created here
&s // We return a reference, but then "s" goes out of scope and is dropped; this is an error since it would produce a dangling reference}-
You could “fix” this by having the function return a String rather than a reference, that way ownership would be moved out, and nothing would be deallocated.
-
Slices (reference)
- Slices don’t have ownership over their elements (they’re a kind of reference).
- They refer to a contiguous sequence of elements.
- String slices (reference)
- A string slice is a reference to a part of a string.
- A string slice is immutable.
- A string slice’s type is “&str”.
- Syntax example:
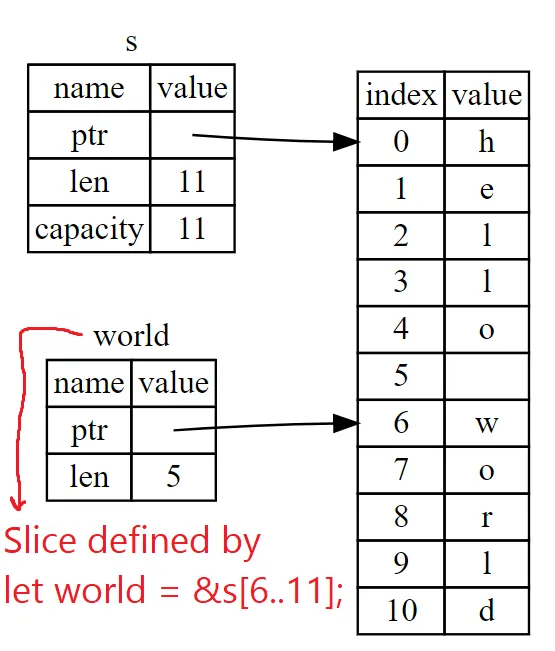
let s = String::from("hello world");
let hello = &s[0..5];let world = &s[6..11];- Memory example from the docs:
-
The length of a slice is ENDING_INDEX - STARTING_INDEX (so 5 in both examples above).
-
Just like Python’s slicing (except without the colon), you can omit either or both of the starting/ending numbers:
- &s[0..]
- &s[..len]
- &s[..]
-
Slices, by virtue of being immutable, will let you avoid errors like this (reference):
fn main() { let mut s = String::from("hello world");
let word = first_word(&s); // this returns a slice
s.clear(); // This errors because the slice is immutable but "s" is mutable and we're trying to modify it. Rust doesn't allow a mutable reference to something in the same scope where an immutable reference exists.
println!("the first word is: {}", word);}- When defining a function’s parameters, prefer a string slice (&str) over a String to make your code more general (reference). String literals already are string slices, so you can pass in a String or a &str.
- Other slices (reference)
- You can have slices into arrays like so:
let a = [1, 2, 3, 4, 5];let slice = &a[1..3]; // the slice's type will be &[i32] (ampersand with square brackets → slice type)-
You can also slice into Bytes, String, PathBuf, etc.
-
Structs (reference)
struct Color(i32, i32, i32);let black = Color(0, 0, 0);- The variables of a struct are called fields.
- Sample syntax:
// Define a structstruct User { username: String, email: String, sign_in_count: u64, active: bool,}
// Instantiate a struct// Note: if we already had a variable in scope named "email", we could just type "email" with no colon and it would get that value (reference)let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1,};
// Access a memberuser1.email
// Change a member (assuming you made the struct mutable with "let mut user1 = User …"user1.email = String::from("whatever");- An entire struct instance has to be mutable; you can’t change individual fields’ mutability.
- Just like JavaScript’s spread operator, ”..” can be used in Rust to copy any properties from another struct (reference):
let user2 = User { email: String::from("another@example.com"), ..user1 // move all fields from the user1 struct (changing ownership)};- Also just like JavaScript, you can use shorthand for initializing fields when they match parameter names:
fn build_user(email: String, username: String) -> User {User {email,username,active: true,}}-
There are tuple structs which have anonymous fields (reference). However, it’s usually better to just explicitly name your fields (reference).
-
Unit-like structs are structs without any fields (reference). They’re useful when you want an explicit struct name without data associated to it, e.g. when you want to add traits.
-
Without lifetimes, you can’t easily store references like string slices (&str) since you want instances of a struct to own all of the struct’s data for the time the struct is valid (reference).
-
If you want to be able to println! an instance of a struct, you have some options (reference):
- Add #[derive(Debug)] before the struct’s definition and print with something like ”{:#?}“.
- Implement the std::fmt::Display trait. This grants the to_string method.
-
Methods (reference)
- Methods are just functions that are part of structs, enums, or trait objects (reference). Their first parameter is always “self” (and unlike Python, “self” is a keyword, not just a convention).
- Similarly, “Self” (capitalized) is an alias for the type that the “impl” block is for. You’ll see this frequently with constructors, e.g. “fn new() -> Self { /body here/ }“.
- Sample syntax:
- Methods are just functions that are part of structs, enums, or trait objects (reference). Their first parameter is always “self” (and unlike Python, “self” is a keyword, not just a convention).
struct Rectangle { width: u32, height: u32,}
// Define a method "area" in the Rectangle struct// Note: you can have multiple "impl" blocks (reference)impl Rectangle { fn area(&self) -> u32 { self.width * self.height }}
// Instantiate the structlet rect1 = Rectangle { width: 30, height: 50,};
// Invoke the methodrect1.area()- Multiple “impl” blocks are possible and are used for generics.
- Associated functions for structs (AKA “static functions”) (reference)
- If you don’t take “self” as the first parameter, then a function will be an associated function rather than a method.
- Sample syntax:
struct Rectangle { width: u32, height: u32,}
impl Rectangle { // This is an associated function since it doesn't take "self" fn square(size: u32) -> Rectangle { Rectangle { width: size, height: size, } }}
// This is how we call itlet sq = Rectangle::square(3);-
This is essentially how Rust does constructors. “new” is the conventional name for such an associated function, but it’s not a special name and isn’t required.
-
Collections (reference)
- All collections are stored on the heap and can grow or shrink as needed. The most common ones are vector, string, and hash map.
- While collections like a vector have to store the same type of element (since its definition is Vec<T>), you can make an enum with different variants and have T be the enum itself (reference). I assume that the compiler allocates space for each element equal to the size of the largest variant of the enum (e.g. having an i32 and an i64 would mean that each element is 8 bytes).
enum SpreadsheetCell { Int(i32), Float(f64), Text(String),}
let row = vec![ SpreadsheetCell::Int(3), SpreadsheetCell::Text(String::from("blue")), SpreadsheetCell::Float(10.12),];-
They go on to mention that you could use a trait if you didn’t know which types could be allowed (reference).
-
When a collection is dropped, all of its elements are also dropped (reference).
-
Vectors (reference)
- Sample syntax:
// Create an empty vector (this requires the type annotation ("<i32>"))let v: Vec<i32> = Vec::new();
// Create a vector and infer types by using the vec! macrolet v = vec![1, 2, 3]; // this will infer a type of i32
// Create a mutable vector and update itlet mut v = Vec::new();v.push(5);
// Accessing members (there are two ways) (reference)let third: &i32 = &v[2]; // this will panic if there is no element// v.get() returns an Option<&T>match v.get(2) { Some(third) => println!("The third element is {}", third), None => println!("There is no third element."),}
// Iterate over a vector's elements (reference)for i in &v { println!("{}", i);}
// Iterate and mutatelet mut v = vec![100, 32, 57];for i in &mut v { *i += 50;}- Strings (reference)
- Remember to read the differences between str and String here in these notes.
- push lets you push a single character (reference).
- push_str lets you push a string slice (reference).
- Concatenation can be done with + or the format! macro (reference)
// Concatenation involves moving memorylet s1 = String::from("Hello, ");let s2 = String::from("world!");let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used, that way there's only one owner of this memory at any given time- The format! macro bypasses having to specify a bunch of +, ”, and &. It also doesn’t take ownership of any of the parameters.
// The following line…let s = s1 + "-" + &s2 + "-" + &s3;
// …can be written as this:let s = format!("{}-{}-{}", s1, s2, s3);- Hash maps (reference)
- Sample syntax:
// HashMap doesn't exist in the preludeuse std::collections::HashMap;let mut scores = HashMap::new();scores.insert(String::from("Blue"), 10);scores.insert(String::from("Yellow"), 50);
// Iterate over key/value pairslet mut scores = HashMap::new();scores.insert(String::from("Blue"), 10);scores.insert(String::from("Yellow"), 50);for (key, value) in &scores { // we iterate in an arbitrary order println!("{}: {}", key, value);}- You get values with “.get” (just like a vector) which returns an Option<&V> (reference)
- Calling “insert” on a key that already exists will replace the existing value (reference).
- You can use “entry” and “or_insert” to handle a case where you only want to add a value if it doesn’t exist (reference):
let score = scores.entry(String::from("Yellow")).or_insert(50);The way that “Entry” (which is the return value from scores.entry) looks to facilitate this is an enum with two variants: Occupied and Vacant.
-
You could also update a hash map’s value based on the existing value, e.g. incrementing a count (reference).
-
It’s very common to have a string as a key. A HashMap owns its string keys, which means that if something else already owns a string (say, a User struct), then you’d need to clone it to check a corresponding entry in a hashmap. E.g. for this Rustlings example, you would do something like this:
let mut team1 = scores.entry(team_1_name.clone()).or_insert(Team { name: team_1_name, goals_scored: 0, goals_conceded: 0,});team1.goals_scored += team_1_score;team1.goals_conceded += team_2_score;-
Alternatively, you can use the Cow type (“clone on write”) for the keys of the hash map, which allows you to share the string, then when it’s written, it’ll be cloned first. If you want to do this, you may want to get a crate that implements this for you (something like HashCow probably).
-
Error handling (reference)
- Rust has recoverable errors, denoted by returning a Result<T, E>, and unrecoverable errors, denoted by panicking (reference).
- Rust doesn’t have exceptions. The only time a stack is unwound on an error is when panicking with the default behavior. If you don’t want the stack to be unwound (which I imagine is a very rare scenario), you can disable it in Cargo.toml (reference).
- Recoverable errors (reference)
- This is done by returning a Result<T, E>. T represents the value on success, and E the error. Result itself is an enum with “Ok” and “Err” variants.
- Sample syntax (reference):
use std::fs::File;
fn main() { let f = File::open("hello.txt");
let f = match f { Ok(file) => file, Err(error) => panic!("Problem opening the file: {:?}", error), };}- You can match on specific errors, e.g. differentiate between file-not-found and everything else (reference)
- unwrap is a shortcut to panic on an erroneous Result (reference), e.g.
let f = File::open("hello.txt").unwrap();-
Apparently “unwrap” is a code smell in general, and you should use unwrap_or or unwrap_or_else instead to prevent the panic.
-
If you truly do want to use “unwrap”, it’s better to use “expect” since at least then you get a friendly error message.
-
Propagating errors is so common that Rust has the question-mark operator (reference):
fn read_username_from_file() -> Result<String, io::Error> { let mut f = File::open("hello.txt")?; let mut s = String::new(); f.read_to_string(&mut s)?; // if the result is Ok, then the value will be returned from the expression. If it's an Err, then the whole function will return the error. Ok(s)}
// You can even chain calls after the question markFile::open("hello.txt")?.read_to_string(&mut s)?;- Rhymu’s video on error-handling shows how we convert from the long form to one with a question mark
- The question mark will convert from the error type returned to the one that your function’s signature requires. It does this using the “From” trait.
- ⭐ Keep in mind that your Result doesn’t have to have an “Error” in it at all! E.g. you can have a function like this:
fn demo_result(should_error: bool) -> Result<String, String> { if should_error { Err("This failed".to_owned()) } else { Ok("This worked!".to_owned()) }}-
You can only use the question mark from a function that returns a Result, Option, or anything implementing std::ops::Try (reference).
-
[11:27] NathanielBumppo: These days, often you’ll see functions return Result<T, dyn Error> . This allows it to return any error type that implements the Error trait. (reference) (Rustlings reference for an example of how this would look, although keep in mind that the ”???” should be “Error” since it’s intended as an exercise for new Rustaceans)
-
map_err is super helpful when you have something that produces an error but you want to transform it to a different type, e.g. this function.
-
Generic types, traits, and lifetimes (reference)
- Generics (reference)
- The phrasing that the book uses is “a Point<T> is generic over some type T” (reference)
- Code with generics won’t run slower than code with concrete types since it will generate code for all concrete types that you use (reference). This is apparently unlike a language such as Java that will erase generic types completely (reference).
- This process that Rust performs is called monomorphization and will generate types like Option_i32 and Option_f64.
- Sample syntax:
- Generics (reference)
// Defining a function with generics// This takes in a slice with values of type Tfn largest<T>(list: &[T]) -> T { … }
// Defining a struct with generics (reference)struct Point<T> { x: T, y: T,}
// Struct with multiple genericsstruct Point<T, U> { x: T, y: U,}
// Method on the Point<T> struct (reference)// As the docs mention, the <T> right after "impl" is needed so that// we know that Point<T> doesn't refer to a concrete type (see// reference link if that doesn't make sense).impl<T> Point<T> { fn x(&self) -> &T { &self.x }}
// Enum definition with multiple generics (reference)enum Result<T, E> { Ok(T), Err(E),}- Traits (reference)
- Traits define shared behavior in an abstract way. They’re like interfaces in other languages.
- When used with generics, trait bounds (also just termed bounds) say that a generic has to have a certain set of traits (AKA “the generic implements Trait T” in other languages (Java example here)).
- Trait bounds take two forms. Suppose you have two different structs that implement a trait, and you want to be able to take in either one to a function (e.g. this example where the ”??” are placeholders). You can do this in two ways:
fn compare_license_types(software: impl Licensed, software_two: impl Licensed) -> bool {fn compare_license_types<T: Licensed, U: Licensed>(software: T, software_two: U) -> bool {The important thing to note here is that you need two trait bounds so that the two software parameters can be of different types.
- Thanks to coherence and the orphan rule, you can’t implement an external trait on an external type, that way, you can trust that your code won’t be modified by some external crate (reference).
- You can conditionally implement functions for a type based on which traits the type implements (reference). This is termed blanket implementation. For example, the standard library implements ToString on any type that also happens to implement the Display trait:
impl<T: Display> ToString for T { // --snip--}-
This lets you call ToString on any type that implements the Display trait.
- This is why it’s sometimes hard to search for where a particular function is coming from. For example, i32 has ToString as a result of Display, but it comes from a blanket implementation. The docs tell you that, which is why I assume it’s important to run “cargo doc” on your own code if you’re confused.
-
Default implementations of traits can call other methods in the trait even if they don’t have their own default implementations (reference). For example:
pub trait Summary { fn summarize(&self) -> String;
// This is a default implementation, and it can call summarize() fn capitalize_summary(&self) -> String { capitalize(self.summarize()) // note: we assume capitalize() exists somewhere }}- You have full ownership of self when it comes to implementing a trait.
For example, if you have this trait:
trait AppendBar { fn append_bar(self) -> Self;}…then you can implement the method this way:
fn append_bar(mut self) -> Self { self.push("Bar".to_owned());
self}- Sample syntax:
// Define a traitpub trait Summary { fn summarize(&self) -> String;}
// Implement that trait for a structpub struct Person { pub name: String,}impl Summary for Person { fn summarize(&self) -> String { format!("Name: {}", self.name) }}
// Function that returns a type that implements a trait (reference)fn returns_summarizable() -> impl Summary { … }
// Trait with default implementation (reference)pub trait Summary { fn summarize(&self) -> String { String::from("(Read more...)") }}
// Use a trait's default implementationimpl Summary for Person {} // this is intentionally empty. If you had non-default implementations alongside summarize, then you would need to fill this out with their implementations.
// Traits as parameters (reference) - this says that "item" needs to implement the "Summary" trait. This is a trait bound (the docs seem to say that even "impl Summary" is a trait bound).pub fn notify(item: &impl Summary) { println!("Breaking news! {}", item.summarize());}
// The "item: &impl Summary" syntax is sugar for: (reference)pub fn notify<T: Summary>(item: &T) { println!("Breaking news! {}", item.summarize());}
// Note that if you use trait bounds as follows, the arguments must be of the same typepub fn notify<T: Summary>(item1: &T, item2: &T) {}
// Specifying multiple traits with "+"pub fn notify(item: &(impl Summary + Display)) { … }pub fn notify<T: Summary + Display>(item: &T) { … }
// If you have too many trait bounds, it's helpful to use "where" (reference)// This…fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 { … }// …becomes this:fn some_function<T, U>(t: &T, u: &U) -> i32 where T: Display + Clone, U: Clone + Debug{ … }- Lifetimes (reference)
- Confused about lifetimes? I found this video to be helpful for beginners.
- Related to memory ownership is the concept of lifetimes. Lifetimes represent the scope for which a reference is valid (reference).
- The whole point of lifetimes is to prevent dangling references (reference, what is a dangling reference)
- Borrow checker (reference)
- This is the mechanism that the Rust compiler uses to determine whether a borrow should be valid. Remember that a borrow is essentially a temporary change in ownership of any particular value since every value has exactly one owner (it’s not really a change in ownership, just like how when you borrow a book from someone, you don’t own it for that time). Thus, when you pass a value to a function without the reference operator (”&”), you’re moving ownership to that function, and the caller can no longer use the value unless the function were to explicitly pass ownership back (by returning the value or using a reference to it).
- The borrow checker doesn’t always have enough information to be able to determine the lifetime of a particular value. This is just like how Rust can’t always infer a variable’s type without an additional specification from the programmer. Consider the following code (reference):
fn longest(x: &str, y: &str) -> &str { if x.len() > y.len() { x } else { y }}- This code cannot be analyzed on its own by the borrow checker. We’re either returning a reference to x or to y, but it’s impossible to tell at compile time from this function definition alone. The error you get is “this function’s return type contains a borrowed value, but the signature does not say whether it is borrowed from
xory”. This is essentially saying “we don’t know who should own the return value”. Without knowing the owner, we don’t know when to free the memory when the owner goes out of scope, which means we don’t know how long the value should live for. - To fix such issues, we use the lifetime annotation syntax (reference). This requires an apostrophe and typically is a single lowercase letter. Examples:
&'a i32 // a reference with an explicit lifetime&'a mut i32 // a mutable reference with an explicit lifetime-
The annotations do not change how long the references live for. Instead, they simply specify relationships between references. For example, annotating two parameters with ‘a (with the apostrophe) just indicates that they live for the same length of time as one another.
- [11:15] Patatas_del_papa: This comes from the rust lang forum and I hope by the end of this chapter makes sence “You don’t declare lifetimes. Lifetimes come from the shape of your code, so to change what the lifetimes are, you must change the shape of the code.”
-
Lifetime annotations in function signatures (reference)
- Sample syntax:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y }}- As shown in the example that defines a function named “longest”, we have a generic lifetime, ‘a, which will be bound to a concrete lifetime when the function is invoked. The value of that concrete lifetime is equal to the shorter of the two arguments’ lifetimes. Likewise, the return value has the same lifetime (i.e. it’ll also be the shorter of the arguments’ lifetimes).
- To demonstrate this:
fn main() {let string1 = String::from("long string is long");
{ let string2 = String::from("xyz"); let result = longest(string1.as_str(), string2.as_str()); println!("The longest string is {}", result);}}
-
There’s an “outer” lifetime and an “inner” lifetime since there are two scopes defined. As mentioned already, ‘a is bound to the shorter of the two, which is the “inner” lifetime. Thus, the result string slice will be freed after the inner lifetime. It’s just a reference, so freeing it won’t make string1 unusable.
-
This quote from the docs is quite helpful: “When returning a reference from a function, the lifetime parameter for the return type needs to match the lifetime parameter for one of the parameters.” (reference). For example:
fn return_first_param<'a>(x: &'a str, y: &str) -> &'a str { x}-
We know that this function always returns “x”, but that still doesn’t allow us to omit the lifetime annotations altogether, because then the return value’s lifetime wouldn’t match one of the parameter’s lifetimes, and we’re returning a reference.
-
Lifetime annotations in structs (reference)
struct ImportantExcerpt<'a> { part: &'a str,}-
This says that an instance of ImportantExcerpt can’t outlive the “part” reference that it holds, i.e. it must live at most as long as “part”.
-
Lifetime annotations on method definitions (reference)
- Look at the reference link for syntax/examples. This doesn’t really add anything new given that the notes already cover functions and structs.
-
Lifetime elision (reference)
- Historically, you used to have to annotate every single lifetime. The reference link basically says that you may have to annotate even fewer in the future as the compiler evolves and can infer more about your code’s lifetimes. Elision just means omitting something, and in this case, it means you omit the explicit lifetime declaration in certain cases.
- The link goes on to describe the rules that are currently applied to figure out whether lifetime annotations can be inferred.
- Rule #1: each reference parameter in a function will be assigned their own generic lifetime, e.g. ‘a for the first reference, ‘b for the second, etc.
- Rule #2: if there’s exactly one lifetime parameter (meaning the function only has a single reference parameter), then all output parameters will be annotated with that same lifetime.
- If you have more than one parameter, then this rule doesn’t apply even if they both use the same lifetime.
- Rule #3: in methods where self is a reference (i.e. “&self” or “&mut self”), the lifetime of self is assigned to all output parameters.
- If, after applying all of those rules, the compiler can’t figure out the lifetime of any references, then it will produce an error.
-
Static lifetime (reference)
- It’s denoted by ‘static.
- This is a special lifetime that indicates that a reference lives for the entire duration of the program.
- All string literals have a ‘static lifetime.
- They suggest using it only if you’re positive that you want the resulting behavior. I.e. there are some errors that will suggest it, but they’re indicative of dangling references or lifetime mismatches.
-
Testing (reference)
- When you make a library crate, you’ll automatically get a test module (reference): cargo new project_name —lib:
#[cfg(test)]mod tests { #[test] fn it_works() { assert_eq!(2 + 2, 4); }}-
The “cfg” attribute is needed to make sure the tests aren’t distributed with your library (reference). This is only needed by tests in the same directory as the code under test, so typically integration tests wouldn’t have this (reference).
- Technically, the “cfg” attribute is just looking for a particular configuration value (in this case “test”).
-
As shown above, annotate using the #[test] attribute to mark something as a test (since you may have utility functions in your testing files).
-
You can ignore tests with the ”#[ignore]” attribute (reference)
-
Assertion macros
- assert!(cond)
- assert_eq!(op1, op2) - compare equality and print both values if the assertion fails
- You can also add a custom message (reference):
assert_eq!(a, b, "we are testing addition with {} and {}", a, b);- Note: Rust doesn’t have a convention for argument order like how Node.js expects the “actual” value first (reference)
- In order for this to work, your values need to have implemented the PartialEq trait for comparing equality and the Debug trait for printing the value if the assert fails(reference)
- They suggest using a derive annotation for this
#[derive(PartialEq, Debug)]This will generate default implementations for each trait (reference).
-
PartialEq is not the same as the Eq trait. Part of the reason why these are different is because two instances of NaN should not be equal to each other.
-
assert_ne!(op1, op2) - same as asserteq but with _inequality
-
Failures
- If you want a test to fail (e.g. you get to code that should be unreachable), use the panic! macro.
- If you expect code under test to fail, use the should_panic attribute (reference). The test will then succeed if a panic happens and fail if it doesn’t.
- Keep in mind that your test could panic for any reason, including something that you didn’t have in mind like a mistyped test (e.g. passing an empty string where you didn’t mean to). For that reason, you can pass a string to should_panic that will be compared against (via substring) the panic message.
- If you want, you can have a function return a Result, that way you can use the question-mark operator as shown below:
{ #[test] fn it_works() -> Result<(), String> { // If this fails, we'll fail the test because we'll return Err some_function_that_returns_a_result()?;
if 2 + 2 == 4 { Ok(()) } else { Err(String::from("two plus two does not equal four")) } }}- It’s typical to bring everything from the outer scope into the inner scope with a “use” directive:
mod tests { use super::*;
// … test code goes here …}-
This even works for pulling private functions into a test’s scope (reference).
-
Conventions
- Unit tests: the convention for unit tests is apparently to make a “tests” module in the same file where the functions are defined (reference)
- Integration tests
- You typically put your integration tests into a “tests” directory that uses your library like any other consumer would (i.e. it wouldn’t be able to call private functions). Cargo will actually look for the “tests” directory (reference).
- There’s no need to annotate code with #[cfg(test)] since integration tests are treated specially.
- If you want common functionality for test code that isn’t explicitly a test, look at this link for how to do so; apparently it’s different from the normal module system.
- You typically put your integration tests into a “tests” directory that uses your library like any other consumer would (i.e. it wouldn’t be able to call private functions). Cargo will actually look for the “tests” directory (reference).
-
Smart pointers
- Note: I haven’t officially read this chapter of the book yet (as of 12/18/2022)
- A note on Box: https://stackoverflow.com/a/29848802/3595355
String vs. str
Section titled “String vs. str”Keep in mind that &str and std::string::String are completely different types even though they share many of the same methods.
let a = "hello"; // type is &str (AKA "string slice" or "string literal")let b = String::from("hello"); // type is String (technically std::string::String)- A good way to remember this is to think of slicing letters off of “String” to get “str”, which means “str” is a string slice.
- A string literal is a string slice already (reference).
- A string literal (like “Hello”) is stored in the text section of the executable itself since it’s known at compile time. Thus, its lifespan isn’t the same as regular variables since it lives both on the hard drive and in memory. This is called a “‘static” lifespan (intentionally with that apostrophe at the beginning).
- You slice a string by bytes, not by graphemes. This doesn’t matter too much for English, but it matters for Unicode-based languages (reference). However, even though you slice by bytes, you can’t slice in the middle of a character boundary. For example:
// Slice the first two characterslet hello = "Здравствуйте";let s = &hello[0..4];println!("{}", s); // prints Зд
// Slice the first byte (erroneous way)let s = &hello[0..1]; // ERROR - "byte index 1 is not a char boundary"
// Correct way to slice the first bytelet s = hello.bytes().nth(0); // returns an Option<u8>- If you need the individual characters, you can use the built-in .chars() method (reference)
Whether you use to_string, String::from, or to_owned to get an owned string doesn’t matter (reference)
The String “extend” function
Section titled “The String “extend” function”I found this function difficult to write out as a newbie (the goal is to use an iterator to capitalize the first letter of a string). moussx_ from the stream shared this code with me to make it easier with the “extend” function:
fn main() { println!("{}", capitalize_first("hello"));}
fn capitalize_first(input: &str) -> String { let mut s = String::new(); let mut c = input.chars(); if let Some(first) = c.next() { s.extend(first.to_uppercase()) } s.extend(c); s}Cargo basics
Section titled “Cargo basics”- Basics
- Development vs. release (reference)
- All cargo commands build debug versions by default. These are unoptimized and intended for development. The “—release” flag is what you’d use for production versions.
- Development vs. release (reference)
- Create a project
cargo new name_of_projectcd name_of_projectThis also initializes a Git repository. If you don’t want that, use “cargo new name_of_project —vcs none”.
- Add a crate
cargo add regex- Build a project
cargo build [--release]- Build and run a project (if it was modified since the last run (reference))
cargo run [--release]- Clean out build artifacts (remove everything that cargo has built)
cargo clean- Ensuring code correctness
- Check if a project would build without actually building it (reference)
cargo checkThis is faster than building and will also build dependencies.
- Lint
cargo clippyThis is a strict linter called “rust-clippy”. You can use this instead of “cargo check”.
-
Both “cargo check” and “cargo clippy” share the same cache currently, so you may need to use “cargo clean”.
-
Update crates (reference)
cargo updateRust does follow semver, but by default, it assumes that you have ”^” before all version numbers. E.g. “0.5.0” is really “^0.5.0”, meaning this will update to 0.5.6, but not to 0.6.0. For that, you’d have to manually modify your Cargo.toml file.
- Test code (reference)
cargo test-
You can alter exactly how the tests run (reference). By default, they’ll run in parallel and hide all output.
- To get help on this: cargo test —help
- To run on a single thread: cargo test — —test-threads=1
- To show output: cargo test — —show-output
- To run a set of tests (reference): cargo test substring_that_appears_in_test_name
- If you want the argument to be treated literally and not as a substring, use “cargo test tests::exact_test_name — —exact”
- To run ignored tests: cargo test — —ignored
-
Generate documentation for your whole project
- Create (from a project directory)
cargo docThis will likely take a while the first time, but then on subsequent times, it’ll only document what changed.
- Open
cargo doc --openRustup basics
Section titled “Rustup basics”- Open documentation locally
rustup docExamples
Section titled “Examples”io::Result
Section titled “io::Result”Basic Rust stuff, but I was a little confused about how to produce an error at first. Here’s an example:
fn main() { match ensure_is_directory(Path::new("./main.rs")) { Ok(msg) => println!("Success: {}", msg), Err(why) => println!("Error: {}", why), }}
fn ensure_is_directory(dir: &Path) -> io::Result<&str> { if dir.is_file() { Err(io::Error::new( ErrorKind::Other, "The path you passed is a` file, not a directory", )) } else { Ok("You're good!") }}This will print “Success: You’re good!” as written, but “Error: The path you passed […]” if you pass “./” instead.
Notes:
- At the time of writing (11/13/2022), NotADirectory is still an experimental API, but that would be an appropriate ErrorKind to use.
- Returning a Result<&str> just to print a success message isn’t very important and can be replaced with the unit type: Result<()>. Then, the “Ok” line would return “Ok(())”, and we would get rid of “msg” and replace it with ”()“.
Troubleshooting
Section titled “Troubleshooting”expected (), found integer
Section titled “expected (), found integer”As a simplified example:
fn foo() -> u32 { if true { 5 } 6}I’d intended for the line with “5” on it to be “return 5;“. Omitting that will actually make Rust tell you that you forgot a “return”, but that’s because I simplified the example to where it knows to do this. In other cases, you may see “expected (), found integer”. The explanation for this comes from here: “The () type has exactly one value (), and is used when there is no other meaningful value that could be returned.” In this case, the “if” has no meaningful return value. If you do swap “5” with ”()”, the function will always return 6.
In other words, Rust may not be able to tell that you wanted to return from the function since the “if” itself has a return value, but it’s not captured anywhere. Compare that to this function which always returns 5:
fn foo() -> u32 { let x = if true { 5 } else { 6 }; // the result of the "if" is stored in x x}expected &str, found struct std::string::String
Section titled “expected &str, found struct std::string::String”[10:47] LaikaDoggo: Rust has a String, which you own, and a str, which is a String you do not own
“str” is called a “string slice”.
This happened when I had this line of code:
let guess = guess .trim() .parse::<u32>() .expect(format!("You needed a number but typed {}", guess)); // ❌I just needed an ampersand in front of “format”:
let guess = guess .trim() .parse::<u32>() .expect(&format!("You needed a number but typed {}", guess)); // ✅I wrote more details about this in the String vs. str section.