Engineering interview prep
Created: 2020-06-26 08:48:44 -0700 Modified: 2020-09-23 18:31:06 -0700
Free sites to use for technical prep
Section titled “Free sites to use for technical prep”Solve coding problems:
- HackerRank
- Codewars
- CodeSignal - it’s paid for companies, but not for developers
- LeetCode
- Make sure to look at a question’s upvote-to-downvote ratio. The ones with downvotes piled high are generally bad questions.
- Make sure to look at a question’s upvote-to-downvote ratio. The ones with downvotes piled high are generally bad questions.
(↑ probably good)
(↑ probably bad)
-
Don’t put a lot of stock into the “You are faster than X% of people” since it can change wildly without even modifying your answer
-
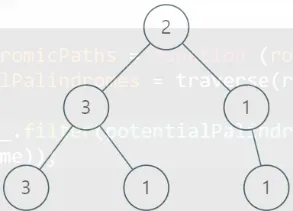
There’s a tree visualizer if you click Console → Testcase → Tree visualizer, that way you can turn something like [2,3,1,3,1,null,1] into this:
-
Project Euler - this is more for math than for algorithms
-
Advent of Code - a yearly set of 25 problems
Other resources:
- Great rundown of “you suck at the coding interview” with specific tips and resources on how to improve
- Google’s techdevguide: https://techdevguide.withgoogle.com/ (it has VERY detailed hints/explanations)
- My videos where I was personally preparing (as opposed to teaching): Technical Interview Preperation
- Big-O cheat sheet: https://www.bigocheatsheet.com/
- Recorded videos: https://interviewing.io/
- Learning algorithms: https://www.geeksforgeeks.org/
- Cracking the Coding Interview (it’s a paid book). I used this many years ago and liked it well enough.
Summary of my overall learnings
Section titled “Summary of my overall learnings”SUPER high-level summary (more details in the next sub-section)
Section titled “SUPER high-level summary (more details in the next sub-section)”- Practice, practice, practice!
- Interviews are mostly about your thought process, not your solution
- Write unit tests while practicing
- Be positive during an interview
- Don’t give up when you encounter difficulties
- Simplify problems to base cases or sub-problems
- Don’t eat a large lunch during a set of interviews
- Iterators and generators can do quite a lot!
- If your resulting code is longer than about 5-10 lines, then you can probably simplify it.
Go easy on yourself
Section titled “Go easy on yourself”There’s something that I struggled with for a while after I was 100+ hours deep into practicing: I wasn’t sure if I’d learned anything after doing some problems. For example, the first time you do a binary-search problem, there are key takeaways like how to write the search or how doing so improved the time complexity. After you’ve done a few such problems, you ideally start to see patterns that hint at when you would use a binary search.
As you do problems, these conscious learnings of when to apply algorithms or data structures will decelerate. I.e. you eventually know how DFS works, when you’d use a heap, and why sorting your input first might be a good idea. After that point, the bulk of what you learn is likely subconscious; you’re honing heuristics that will hopefully help steer you toward a better/faster solution.
Put differently: at some point, you may find yourself saying “huh, I should have seen that” without any real learning to take away from the problem.
Perhaps, when that happens, it means you’re done practicing. Perhaps it means that you just have to drill these patterns even deeper into your head. Either way, I still felt shoddy after failing to solve some easy problems after so many hours.
Something struck me that made me feel a little better: you can abstract “solving coding problems” out to just “solving problems”, and no one in their lives gets to the point where they have no problems. To me, this means a couple of things:
- Targeted practice will only be helpful to a certain point; there will always be problems that stump you.
- There are diminishing returns to practicing. I feel like I have a sliding window in my head of all of the technology information I’ve ever learned.
Problem-solving frameworks
Section titled “Problem-solving frameworks”Technical interview
Section titled “Technical interview”This is the flow I go through when I’m given a technical question. I find that the actual time spent coding is typically very little if I write my algorithm and pseudo-code well.
- Understand the problem
- Come up with the algorithm and weigh trade-offs (time/space complexities)
- Test the algorithm
- Write pseudo-code
- Test the pseudo-code
- Write code
- Test the code
Details
Section titled “Details”- Preparing for an interview
- Start with training wheels. I.e. look at hints for the problems, use the Internet to look for pseudocode, etc. You shouldn’t jump right to the “performance” of mock (or actual) interviews if you haven’t practiced!
- For example, I hadn’t written a binary search in forever and didn’t think to track the left and right search indices (see the algorithm here), so I did something completely wrong. Coming up with the concept of tracking “left” and “right” can be difficult under pressure, but it’s a relatively basic concept to remember while approaching a problem, so make sure to practice!
- Look at other people’s solutions! Sites like LeetCode have tons of submissions. Usually, you’ll find an elegant and easy-to-understand solution, and you should figure out what might have gone wrong with your solution and how you could have arrived at the same conclusion for next time.
- Start with training wheels. I.e. look at hints for the problems, use the Internet to look for pseudocode, etc. You shouldn’t jump right to the “performance” of mock (or actual) interviews if you haven’t practiced!
- During an interview
- Technical questions
- The interview should be more about your thought process than your actual solution. As a result:
- Think aloud as much as possible
- Whenever you hit a wall, try to make progress somewhere (debug, handle a base case, etc.)
- Stub functions that you know will exist, and write the parts of functions that you already know. For example, let’s say you have to write a function findSumOfArray. You know that it has to set a sum and return it, so you could stub this out at first:
- The interview should be more about your thought process than your actual solution. As a result:
- Technical questions
function findSumOfArray(arr) {let sum = 0;
// You may not know the code that should go here yet, but the lines above and below are more obvious
return sum;}- While practicing, write unit tests directly into your solution. For example, suppose you need to write isPalindrome:
function isPalindrome(someString) {// your code would go here for the interview}
function test(someString, expectedOutput) {assert.equal(isPalindrome(someString, expectedOutput));}
test('13531', true);test('Adam', false);-
This will greatly help if you’re working in an online coding environment and you find that your solution doesn’t work, so you rework it, then you find that it doesn’t work for a different problem. You won’t need to remember each case as you go and you can test locally.
-
I don’t advise doing this during an interview because jumping directly to debugging or toggling numbers/booleans in your code may be seen as a weakness, but this is still great for practicing.
-
No need to write a function whose implementation would be very basic; you can just write out a call to it and say what it would do and maybe even how you’d write it.
-
When you’ve got your algorithm, ask the interviewer if you should pursue that as a path. Maybe they’ll want to nudge you in a particular direction.
-
DFS/BFS/pathing/tree problems
- A clever trick to make it so that you don’t have to keep track of the entire path that you’ve traversed so far (e.g. if back-tracking is not allowed) is to mark the node as visited just before you continue the search, then mark it as unvisited right after.
- For an example, look at this solution to Path with Maximum Gold.
- A clever trick to make it so that you don’t have to keep track of the entire path that you’ve traversed so far (e.g. if back-tracking is not allowed) is to mark the node as visited just before you continue the search, then mark it as unvisited right after.
-
Mental state
- Be positive! I think of interview rounds sort of like tournament games where if you get too dejected at the beginning, it’ll affect your performance later.
- Keep trying! There are many times where it seems like you’ve exhausted all avenues for a problem. When that happens, try to think of your general techniques:
- Compare the problem to another one
- Simplify the problem
- Try a different approach
- Stick to what you practiced. If you have a mental flow, try to follow the same thing you did while practicing.
- Try to get some variety in your practice. Doing LeetCode for days on end can be demoralizing even if you’re making progress.
- For me personally, if I see a problem structure that may involve recursion (e.g. a tree) and I can’t get the solution, then I usually need to spend longer on the base cases to observe some property that will let me break the problem down even further. A good example of this is this problem.
-
Food
- Digesting food make brain work bad.
-
Specific technical learnings
- Iterators / generators
- Iterators/generators or even just a functional approach may help you minimize off-by-one errors due to how you encapsulate the iteration.
- When people in chat would share their solutions, sometimes they’d approach many problems from an iterator/generator perspective. For example, m_brax wrote the following code for this problem:
- Iterators / generators
var backspaceCompare = function(S, T) { const sKeys = new PeekIterator(iterPressKeysFrom(S)); const tKeys = new PeekIterator(iterPressKeysFrom(T));
while (sKeys.hasNext() && tKeys.hasNext() && sKeys.peek() == tKeys.peek()) { sKeys.step(); tKeys.step(); }
return !sKeys.hasNext() && !tKeys.hasNext();};
function* iterPressKeysFrom(presses) { let numBackSpaces = 0; for (let i = presses.length - 1; i >= 0; --i) { if (presses[i] === '#') { ++numBackSpaces; } else if (numBackSpaces > 0) { --numBackSpaces; } else { yield presses[i]; } }}
class PeekIterator {
constructor(iterable) { this.iterable = iterable; this.next = null; this.advance(); }
hasNext() { return !this.next.done; }
step() { const ret = this.next.value; this.advance(); return ret; }
advance() { if (!this.next || !this.next.done) this.next = this.iterable.next(); }
peek() { return this.next.value; }}- In JavaScript…
- Example coroutine:
function* countToN(n) { for (let i = 0; i < n; ++i) { yield i; }}- Example call:
const iter = countToN(10);while (true) {const {value, done} = iter.next();if (done) break;// use value}- Finding a needle in a haystack (i.e. substring searching)
- The naïve approach is to iterate over both strings and see if the needle appears at the current position in the haystack. However, there are some common improvements that are probably worth being aware of without necessarily knowing how to implement them: KMP (Knuth-Morris-Pratt) and Rabin-Karp (JavaScript implementation here—it’s really not too bad to understand). KMP works by reusing information about partially matched characters. Rabin-Karp works by computing a rolling hash that is quick (e.g. turning a string into a number representation) and then only checking equality if the hashes are equal. Aho-Corasick is another algorithm for matching lots of needles (e.g. a dictionary) in a haystack.
- Clarification about Rabin-Karp:
- The naïve approach is to iterate over both strings and see if the needle appears at the current position in the haystack. However, there are some common improvements that are probably worth being aware of without necessarily knowing how to implement them: KMP (Knuth-Morris-Pratt) and Rabin-Karp (JavaScript implementation here—it’s really not too bad to understand). KMP works by reusing information about partially matched characters. Rabin-Karp works by computing a rolling hash that is quick (e.g. turning a string into a number representation) and then only checking equality if the hashes are equal. Aho-Corasick is another algorithm for matching lots of needles (e.g. a dictionary) in a haystack.
13:54 XCSme If you search a needle of length N, you always store a hash of length N. You always remove oldest character from hash and add new one.
13:55 XCSme Eg: a[bcd]e -> ab[cde] , where [] is the thing you stored the hash of
- General approach to a problem:
- Ensure that you understand the problem (and ask questions!). If examples are given, make sure they make sense to you. It’s easy to miss constraints and then solve a completely different problem.
- Completely come up with the algorithm first
- Weigh the trade-offs
- Think aloud
- Test the algorithm on any examples, and treat your code like someone else wrote it (i.e. look for ”<” vs. ”>”, off-by-one errors, etc.)
- Try to come up with edge cases and test them
- Work out any last questions in the algorithm step rather than in code
- Only after all of that should you move to code
- Stacks
- Sometimes, you just need the concept of pushing and popping without actually storing any data, in which case you can use a counter. For example, to see if a string has matching left and right parentheses, you can just count numUnclosedLeftParens rather than making a stack with their indices.
- Tree problems
- You almost always want to simplify binary-tree problems to a base case and then run a solution recursively. At the very least, start by seeing if there’s such a solution.
- If you ever find yourself wanting to keep track of a path from the root to the current node, think of whether you could store something about the path instead. For example, if you want to make sure that a node is the largest of all of the nodes in the path leading to it, then you only need to track the largest value that you’ve seen so far.
- Any time you get a question involving 0s and 1s…
- Can you treat them as numbers? E.g. 0010 === 2 in binary
- Is there any clever bitmasking you can do?
- Backtracking
- Backtracking is essentially a preorder traversal through a tree (and you don’t necessarily need to construct the tree, just visualize how it would be constructed). Here’s an example from m_brax for this problem:
/* basically for backtracking, youre doing a preorder traversal on a search tree
'' <- root
/ \ a A | | 1 1 / \ / \ b B b B | | | | 2 2 2 2
we call it backtracking because for each node,once we are done with it and we are going back up the tree,we pop off elements from the buffer we stored
*/
function letterCasePermutation(S) { const result = []; const buffer = [];
search(result, buffer, S, 0); return result;}
function search(result, buffer, S, index) { if (index === S.length) { // we are at a leaf node result.push([...buffer].join("")); return; }
for (const nei of adjacent(S[index])) { buffer.push(nei); search(result, buffer, S, index + 1); buffer.pop(); }}
function* adjacent(node) { if (!isNaN(node)) { yield node; } else { yield node.toLowerCase(); yield node.toUpperCase(); }}
/*generate way to backtrack:- maintain a result, buffer- think of a search tree we are doing preorder traversal on- [NOTE] if you can map a problem to search tree, its EZ Clap
def backtrack(result, buffernode): if we are at leaf node: - process buffer return
for each neighbor of adjacent[node]: buffer.push(neighbor) // choose backtrack(nei) // explor eneighbor buffer.pop() // unchoose
therefore, backtrack is just state management with the current buffer
what you can do is do breadth first search on this as well if you visualize this tree*/- Gray code (reference)
- This is a number system that only changes one binary bit for each number that we count up. The way you can form this is to write out all binary numbers from 0 to N, then figure out how many bits changed between each pair. The number of bits that changed is equal to the position of the bit that you should change when starting from 0000 to get the Gray code. For example:
| Number | Number of bits changed |
|---|---|
| 0000 | NA |
| 0001 | 1 |
| 0010 | 2 |
| 0011 | 1 |
| 0100 | 3 |
-
Taking just the “1”, “2”, “1”, “3” in the right column, we toggle those bit indices:
- 0000 → 0001 → 0011 → 0010 → 0110 → …
- This sequence forms the Gray code
-
- I wrote a bunch of notes on this in my coding notebook (direct link here) based on MIT lectures.
- Dynamic programming is all about finding sub-problems, so the general technique that I’ve seen is to identify the pattern and then write simple code to match the pattern. For example, if you see that f(N) is based on f(N/2), then you can compute results from 0 to N and not have to compute them again when N is even. This is memoization.
- People suggest writing an iterative solution to potentially save space and give more fine-grained control.
- We need a way of uniquely identifying a subproblem with the fewest number of parameters (which form the “state”). We also need some way of using a subproblem’s result in another problem or subproblem, i.e. we have to find a relationship between the previous state and a current state.
- Top-down
- You try to handle any given problem by first tackling its subproblems.
- For example, suppose you want f(9) and it can be built from f(4) and f(5). You may not actually have the answers to f(4) and f(5), so you compute them in order to get f(9).
- You typically would memoize f(4) and f(5) in case you need them later, e.g. for f(10).
- You try to handle any given problem by first tackling its subproblems.
- Bottom-up
- You handle subproblems first and use their solutions for problems that build on those.
- For example, suppose you have f(4) and f(5) and want f(9). You can use f(4) and f(5) directly to compute f(9).
- You handle subproblems first and use their solutions for problems that build on those.
-
Generating a range of numbers following a specific pattern
- The best way is to figure out if you can generate the pattern directly. For example, if you want to generate A, B, C, BA, BB, BC, CA, CB, CC, BAA, …, then that’s just counting in ternary where A=0, B=1, and C=2.
- An easy way of generating a pattern is to generate all patterns and filter down to what you need. For example, I had a string like “ABC” where I wanted only “AB”, “AC”, and “BC”. I could generate all binary numbers from 000 to 111 and only accept the ones where two bits were on.
-
Recursion
- One thing that’s clicked for other people is to only think of a single stack frame when looking at recursion and seeing if that makes sense rather than trying to figure out how subcalls would look. Essentially, you treat the recursion as a magic answer to the subproblem and stop trying to examine how it would look when called.
- Remember that it’s possible to code any recursive solution as an iterative one. In some cases, this will be desirable so that you don’t exceed the maximum call-stack size.
-
Bitwise operations
- XOR
- It may be helpful to realize that any number XOR’d with itself is 0. For example, suppose you had an array of numbers where every number showed up exactly twice except for one number which showed up once. To find that single number, you could just XOR the entire list.
- XOR
-
Binary trees
- You can represent a binary tree with a one-dimensional array (reference). To find a child of the current element, you would multiply by 2 and add the offset (based on whether you have a 0- or 1-indexed array). To find the parent, you would do the reverse (subtract and then divide by 2).
- Heaps are sometimes implemented as a binary tree.
- Binary search trees can be converted to a sorted array with an inorder traversal. This is sometimes helpful for finding answers, but you could also potentially avoid allocating space for an array by operating on numbers as you do the inorder traversal.
-
Heaps
- To add a new element to a heap backed by a tree (or one-dimensional array representing a tree), you would typically “sift” the element up or down. For example, in a max heap, the root of any subtree is always greater than its children. To add a number, you would add it to the first empty space in the tree and then sift it upward until it’s less than its parent.
- To find the first empty space depends on how you stored your heap in memory.
- If it’s an array or vector, then just add the element to the end and sift it upward.
- If it’s a tree stored with TreeNodes with three properties (value, leftChild, rightChild), then you would BFS through the tree to find the first node missing a leftChild or rightChild (in that order (i.e. left before right)).
- To find the first empty space depends on how you stored your heap in memory.
- Depending on how heaps are implemented, every operation can be big-Theta(1) except for delete-min, which is always O(log(N)) or big-Theta(log(N)).
- To add a new element to a heap backed by a tree (or one-dimensional array representing a tree), you would typically “sift” the element up or down. For example, in a max heap, the root of any subtree is always greater than its children. To add a number, you would add it to the first empty space in the tree and then sift it upward until it’s less than its parent.
-
Finding the top K most frequent elements in an array without sorting (reference)
- Suppose you have an array with 10 elements and you want the most frequent one without sorting (which would be O(N * log(N))). You could count frequencies in a hashmap and then bucketize the hashmap by frequency into arrays of arrays. This outer array would have to be at least as long as the source array since the maximum frequency is the length of the array (10 in this case). Then, you append to the inner array based on the frequency that you find. Once finished, you just find the last-filled frequency bucket and you know you have the most frequent elements (note that there may be multiple). See the reference link for an example. Here’s an example that I wrote for this problem:
var topKFrequent = function (nums, k) { const frequencies = {}; for (let i = 0; i < nums.length; ++i) { const num = nums[i]; if (!(num in frequencies)) { frequencies[num] = { frequency: 0, num, }; } frequencies[num].frequency++; }
const buckets = _.times(nums.length + 1, () => []);
_.forEach(frequencies, ({ frequency, num }) => { buckets[frequency].push(num); }); let topFrequent = [];
while (k > 0) { let topBucket = null; let i; for (i = buckets.length - 1; i >= 0; --i) { if (!_.isEmpty(buckets[i])) { topBucket = buckets[i]; break; } } topFrequent = topFrequent.concat(topBucket); k -= _.size(topBucket);
delete buckets[i]; }
return topFrequent;};-
For alternatives, you could use a heap or quick-select.
-
Converting recursion to an iterative approach
- Just use a stack and a while loop in place of the programming language’s stack that gets used when you call a function. For example, below is a recursive function to count 1+2+…+N:
function recursiveFn(n) { if (n === 1) { return 1; }
return n + recursiveFn(n - 1);}- Here’s the mechanically converted iterative approach using a stack:
function mechanicalIterative(n) { const stack = []; while (n >= 1) { stack.push(n); n--; }
let answer = 0; while (stack.length > 0) { answer += stack.pop(); }
return answer;}- Here’s the more idiomatic way of writing the iterative approach since the stack is unnecessary:
function idiomaticIterative(n) { let answer = 0; for (let i = 1; i <= n; ++i) { answer += i; }
return answer;}- Data structures
- If you want to store only unique values, use a set. I.e. if you find yourself making a hashmap whose values are all “true” just because you need something, then you don’t really need a hashmap.
- Quickselect
- Quicksort is a divide-and-conquer algorithm where you pick a pivot, then you partition the list into two lists of < or > the pivot.
- Quickselect is just for finding the kth smallest value. At the end of each partition, you know the final list index for the pivot itself, so if the index of the pivot is equal to k, then you’ve found the kth smallest value. If not, you continue sorting around the pivot until you do find the correct index. To do this, you only need to recurse into one of the two partitions based on whether the index of the pivot is < or > k.
- Binary search
- A binary search doesn’t necessarily have to be on sorted data; you just need to be able to eliminate half of the data with a condition. That condition, when searching for an exact value, is typically ”<”, ”==”, ”>”, but it could be a function returning an order.
- Binary searching over matrices typically means doing binary searches within some dimension of it, e.g. a row or a column if you know that rows and columns are individually sorted. For example, if you have “height” rows and “width” columns and you know they’re each sorted, you could go through each row and binary search over each column, making the time complexity height * log(width).
- Basic code for a binary search:
let left = 0;let right = array.length - 1;while (left <= right) { const middle = Math.ceil((left + right) / 2); // be careful about this const val = computeSomeValueHere(left, middle, right); // note: this may not take the same arguments, and it may not even a function (i.e. you could just be looking for the number 5 in an array) if (val < middle) { left = middle + 1; } else { right = middle - 1; }}return left;- Important notes:
- If you’d like a generic way of viewing this in Python, you can extract out a predicate:
def lower_bound(lo, hi, predicate): while lo <= hi: mid = (lo + hi) // 2 if predicate(mid): # the predicate is just a function that returns a boolean value hi = mid - 1 else: lo = mid + 1 return lo-
This doesn’t bail out when you find the specific value that you’re looking for, but you have at most log(N) - 1 more attempts to make, so it’s not terrible to keep looking until your “while” breaks.
-
Out-of-memory issues
- If you try solving a LeetCode problem and you run out of memory because you’re testing every value or storing an array or set of every value, then you likely don’t actually need every value; you can probably just keep track of the last one or some rolling count.
-
Linked lists
- If you’re asked to merge or reorder linked lists, remember to update “next” on every node. For example, I had to convert A → B → C into A → C → B, but I’d forgotten to null out B.next, so I created a cycle.
- You can reverse a linked list in-place by keeping track of the previous node and temporarily storing the head’s “next” node before overwriting it to be the previous (reference):
function reverse(head) { let previous; let tmp;
while (head) { // save next before we overwrite node.next! tmp = head.next;
// reverse pointer head.next = previous;
// step forward in the list previous = head; head = tmp; }
return previous;}-
To find cycles in a linked list, people use Floyd’s Tortoise and Hare algorithm. In general, you have a tortoise that moves one element at a time and a hare that moves two elements at a time. If there’s a cycle, they will eventually meet. If there’s no cycle, they’ll both hit the end of the list.
-
Generating all subsets of a set (reference)
- This is just counting in binary, where a 1 represents that you include the answer in the subset. For example, [“A”, “B”, “C”] can form 8 sets: A B C AB AC BC ABC (and the 8th set is the empty set). You could just count from 0 to 2^3 and emit all possible values.
- Alternatively, you can think of a search with duplicates removed. For example, this code will generate all possible combinations of any number of letters for this problem:
var numTilePossibilities = function (tiles) { const answers = [];
search(answers, "", tiles);
return _.uniq(answers);};
function search(answer, pathSoFar, remainingLetters) { if (pathSoFar.length > 0) { answer.push(pathSoFar); // you could prevent duplicates from entering here rather than needing _.uniq later }
if (remainingLetters.length === 0) { return; }
_.forEach(remainingLetters, (letter, index) => { search( answer, pathSoFar + letter, remainingLetters.substring(0, index) + remainingLetters.substring(index + 1) ); });}Given “AAB”, this will return [“A”,“AA”,“AAB”,“AB”,“ABA”,“B”,“BA”,“BAA”]
- Arrays
- Ask yourself some quick questions:
- Will sorting help?
- Will a sliding/rolling window help so that we can analyze as we go?
- In general, can you reuse some piece of the last sliding window to calculate the next window more easily?
- Will working from both ends of the array help?
- Will splitting the problem into an array of [head, tail] work? I.e. can we use a recursive solution where we keep popping off a single element of the array?
- Will keeping track of deltas help? E.g. [1,2,3,4,5] turns into [1,+1,+1,+1,+1].
- Whenever you need to slice arrays, consider just storing where the slice would start and stop, that way you don’t need to allocate new memory for the slice.
- Ask yourself some quick questions:
- Union-find (good video here) AKA “disjoint-set data structure” (decent video here too, watch at 2X)
- This is a helpful data structure for finding cycles in an undirected graph or to find the minimum spanning tree of a graph (the tree that connects all vertices together; see Kruskal’s Algorithm or this video).
- You need to make a bijection, meaning a mapping function that takes your input and maps it all to other unique values. Typically, this would be a hashmap mapping your input to array indices, e.g. {“a”: 3, “b”: 1, “c”: 2, “d”: 0}. Then, your unions and their parents would be represented by an array. Each element in the array represents which element is its parent, and it would start with each element being its own parent, i.e. [0,1,2,3] would be the starting array.
- With the hashmap I defined earlier, the array [0, 2, 2, 1] would indicate that D’s parent is itself, B’s parent is C, C’s parent is itself, and A’s parent is B.
- Since A’s parent is B and B’s parent is C, you could compress the path from A → B → C so that it’s simply A → C. This would allow you to look up a parent in no more than 2 operations (“get A’s parent” followed by “get C’s parent” (when something is its own parent, then it represents the group).
- If you’re not going to use path compression, then merging two groups is simply updating a single element in the array.
- Big-O vs. Big-Theta (reference, reference2)
- TL;DR: Big-O is an upperbound. Big-Theta is an upper and lower bound.
- Technically, anything that is O(N) is also O(N²), O(N³), etc. because the subsequent Big-Os are even “worse” than the first.
- TL;DR: Big-O is an upperbound. Big-Theta is an upper and lower bound.
- Palindromes
- It may be helpful to work from the middle of a palindrome and radiate outward since palindrome “XYZYX” contains sub-palindromes “YZY” and “Z” (and also “X” and “Y”, but those aren’t centered).
- Two-pointer problems (i.e. this category on LeetCode)
- This was a very difficult category for me to do given how many off-by-one errors I’d have in practically every possible location. I improved by doing the following:
- Thoroughly test each case while it’s still pseudocode rather than encountering an error and trying to fix it as code
- Opt for iterators/coroutines even if it’s just to be able to split iteration into a function that’s easier to reason about. With a coroutine, you can test that the sequence is correct in isolation and then you can at least know that you’re operating on the correct data.
- This was a very difficult category for me to do given how many off-by-one errors I’d have in practically every possible location. I improved by doing the following:
System design
Section titled “System design”Questions to ask a company
Section titled “Questions to ask a company”Remember that you’re interviewing the company just as much as they’re interviewing you! Here are some questions that I’ve found helpful:
- Straightforward questions / circumstantial questions
- Job/team
- Is the job remote?
- Who am I speaking to (i.e. is it a technical person, the CEO, etc.)?
- How many engineers are on the team?
- How senior is the team?
- Why are they hiring?
- How many people are they hiring?
- What’s the review process like?
- Is it yearly?
- Are we ranked against each other?
- What do you look for in a candidate?
- Business
- How is the company funded?
- How many customers do you have?
- How much is the company growing?
- Interview process itself
- What are the next steps in the interview process?
- When should I hear back?
- Technologies / methodologies
- What technologies do you use?
- What OS are engineers expected to use?
- What methodologies do you employ? E.g. TDD, agile, etc.
- What is the test coverage like?
- Do you ever do pair programming? If not, would you want to do this?
- Job/team
- Behavioral questions for the engineering team themselves
- How do you feel about your lead and their impact on your work?
- Where else have you worked?What made you choose COMPANY? How long have you been there?
- What’s your [least] favorite thing about working here?
- How often do you work late or on weekends?
- How much have you learned since joining COMPANY?
- Do you like working for COMPANY?
- Knowing what you know now, what are things you wish you knew before you started?
- COVID-related questions:
- How do you do team-building exercises or even just regular communications while everyone is working remote? E.g. do people mostly talk with their webcams on? Is it just voice?
- Bremir13’s suggestions
- “How did COMPANY handle COVID? Were there layoffs? Affordances for working from home?” His reasoning behind asking this is because it will let you know how the company will handle future crises, e.g. by covering themselves as much as possible or by protecting their employees.
- “How is COMPANY supporting remote work? What cultural changes have there been to improve the social integration and foster a sense of team bonding?” Most companies are currently stuck in a holding pattern, just waiting to go back to offices, rather than implementing complex cultural shifts to make remote work effective long term.
Co-workers or bosses as references
Section titled “Co-workers or bosses as references”If you were ever wondering what is asked of one of your references, here are sample questions that a company asked one of my viewers in an email:
- What is your professional affiliation with <candidate>and how long have you known(him/her)?
- How would you describe <candidate>work style in 3-5 words?
- How would you describe <candidate>ability to work up, down and across the organization?
- What is <candidate>track record of performance?
- How does <candidate>react under pressure or when (he/she) is frustrated?
- In your opinion, what is biggest area of professional development?
- What counsel would you give to our manager to create a meaningful environment for <candidate> to flourish and contribute at (his/her) maximum capacity?
- Is there anything else you’d like to share?
- Why do you think <candidate> is looking to make a career move? <if they work at the same place and remarks are about the work environment> do you agree that <company> is like that?
- What will we need to help <candidate> with to ensure their success?
Specific problems and interesting approaches (kw: “micro problems”)
Section titled “Specific problems and interesting approaches (kw: “micro problems”)”- LeetCode zigzag-conversion
- The problem was to output a zig-zagged string, and the best solution seems to be to append to an array of strings. I.e. the solution starts with four strings like this:
- ""
- ""
- ""
- ""
- …and as you encounter characters, you either change the row of the string you’re outputting to by +1 or -1.
- The problem was to output a zig-zagged string, and the best solution seems to be to append to an array of strings. I.e. the solution starts with four strings like this:
- kth happy string of length n
- The only real problem here is forming all happy strings of the specified length, and it’s not that tough if you use DFS and just skip the character you used last. Then, you can easily bail out when you have k strings. Here’s my whole code:
var getHappyString = function (n, k) { return _.defaultTo(generateHappyStrings(n, k)[k - 1], "");};
function generateHappyStrings(targetLength, k, stringSoFar = "") { if (stringSoFar.length === targetLength) { return [stringSoFar]; }
let strings = []; for (const c of ["a", "b", "c"]) { if (stringSoFar[stringSoFar.length - 1] === c) continue;
strings = strings.concat( generateHappyStrings(targetLength, k, stringSoFar + c) );
if (strings.length >= k) { return strings; } }
return strings;}Merging two sorted lists
Section titled “Merging two sorted lists”You can treat them both as queues. Only pop a number off of the correct list. When one list is empty, concatenate the entire other list.
General techniques and how I solved them
Section titled “General techniques and how I solved them”Parsing a string representing a number to base-10 (in JavaScript)
Section titled “Parsing a string representing a number to base-10 (in JavaScript)”function myParseInt(s) { let powOf10 = 0; let num = 0; while (s > 0) { const digit = s % 10; s = Math.floor(s / 10);
num += digit * Math.pow(10, powOf10); powOf10++; }
return num;}