CircleCI
Created: 2018-09-03 21:02:49 -0700 Modified: 2019-10-14 10:58:19 -0700
Basics
Section titled “Basics”- To see what’s changed in CircleCI, you can look at their changelog (reference)
- Jobs/workflows (reference)
- More specific notes on workflows below
- “working_directory” for steps is pulled from the job if not specified. However, ”- checkout” is done in the job’s working_directory. Suppose you have a repo with a “src” folder in it and you set your job’s working directory to “
/repo”. Your “src” folder will end up at “/repo/src”, so your steps’ working_directory would need to access files via “src/foo.c”. - If you’re building a Docker image from CircleCI, then you’ll need a “setup_remote_docker” step (reference)
- Docker layer caching is a premium feature on CircleCI (reference). If you want to use it without paying money, you could work around it by exploiting their local caching layer (which is free) or by using a remote layer to cache (reference).
- If you ever want to modify CircleCI environment variables programmatically, you can use their API for that (reference)
- If you want to reuse workflows, you may want orbs or YAML aliases. I didn’t end up looking into either one.
- 10:44 HiDeoo Adam13531 Then it needs to be rewritten with orbs https://circleci.com/docs/2.0/reusing-config/ - Specifically “Authoring Reusable Commands”
- 10:44 Resu_Baka https://yaml.org/refcard.html Alias indicators: ’&’ : Anchor property. ’*’ : Alias indicator. maybe when you look into that. Which can help you.
- [10:45] CarstenPet: Something similar to this adam .. https://github.com/CircleCI-Public/circleci-demo-workflows/issues/15 ?? .. might not be what you’re searching for
- If you ever want notifications, you can look into orbs (reference). This could be useful if you don’t want a job/workflow to outright fail but you still want to know about error messages coming from it.
- Docker images
- You can trigger CircleCI jobs from the command line (reference)
- To save variables from a command to use later, you can do this (which will save to CircleCI, not the container itself, so don’t worry about whether your shell is sh, ash, bash, etc.:
- run: name: Setup common environment variables command: | echo 'export ECR_REPOSITORY_NAME="${ECR_VERDACCIO_NAME}-image"' >> $BASH_ENVKeep in mind that the specific way that the above is written may not be what you want. See this section.
- To make sure you’re no longer hitting any cached keys from your config.yml, you can just rename all of the keys, e.g.
Convert this:
- save_cache: key: bot-land-ci-yarn-{{ .Branch }}-{{ checksum "yarn.lock" }} paths: - ~/.cache/yarnTo this:
- save_cache: key: bot-land-ci-yarn-verdaccio-{{ .Branch }}-{{ checksum "yarn.lock" }} paths: - ~/.cache/yarn- Use YAML anchors and aliases so that you don’t have to repeat yourself (reference)
- Simple example
# simple YAML anchors and extend example# create an anchor using &anchornamedefaults: &defaults working_directory: path/to/dir
steps: - run: # merge the anchor using <<: *anchorname <<: *defaults name: Testing application command: make test- Configuration reference (reference) - this includes all YAML commands like “run”
- Built-in environment variables like CIRCLE_SHA1 (reference)
- CircleCI Dockerfiles can be found here
- Read how to get values from Terraform here.
- As of October 2018, they gave 1,000 free minutes per month.
- You can specify multiple Docker images like this:
docker:
-
image: circleci/node:8.12
-
image: circleci/mysql:5.7.17
However, what this is doing is creating two separate containers. So the Node image can access MySQL because MySQL is a service exposed to localhost (in much the same way that the official Docker tutorial lets you use Redis from its own container), but something like this may not work how you expect:
docker:
-
image: circleci/node:8.12
-
image: circleci/python:3.6.1
Here, there will still be two separate containers, but since Python is an executable and not a service, you won’t be able to run python3 from the Node container. If you want to run Python on a Node image specifically, read this section of the notes. If you just want to have multiple arbitrary images combined in one with whatever executables you want, then make your own Docker image (see this section).
-
When making a configuration, run whatever commands you want to make “debugging” easier, e.g.:
-
run:
name: Print environment variable
command: echo Env var is $some_env_var
An executor is what kind of back-end to run on: Docker, machine, or macos (useful for iOS apps).
Workflows
Section titled “Workflows”Workflows are just a collection of jobs that get run in a logical group called a “workspace” (reference). When you run a command like “persist_to_workspace”, it will create a “workspace” directory inside of your working_directory for the job. This persists between jobs in the same workflow so that you can cache assets between jobs. Keep in mind that persist_to_workspace doesn’t have a working_directory property of its own and will always inherit from the job’s working_directory.
- Workflows can be set for manual approval, that way they don’t run without user intervention in the UI (reference)
- If you’re going to do this, make sure that you have a “dummy job” set for approval, i.e. just name it “hold” (although make sure you don’t already have a main job named “hold”).
- If you have multiple workflows that need approval, then they can all have a job named “hold”. What you’ll see in GitHub is something like this
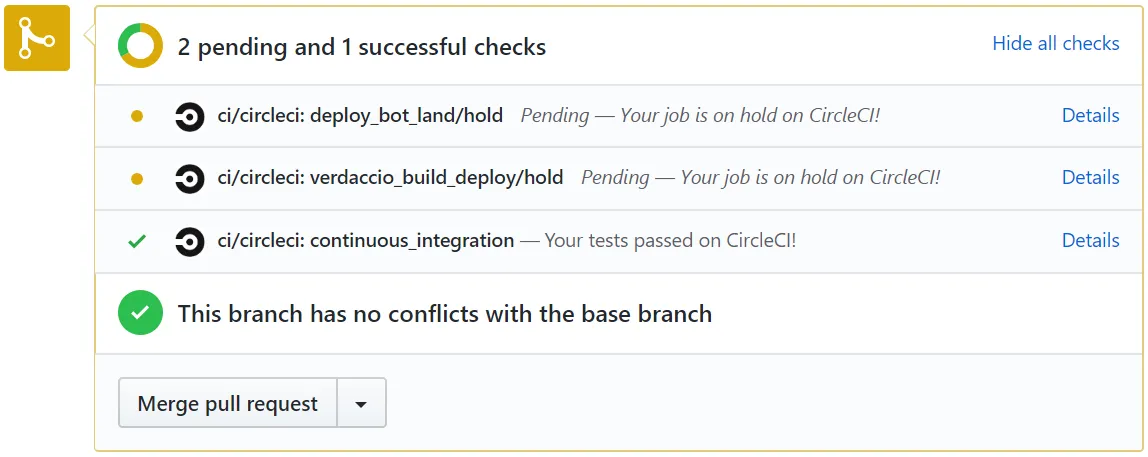
- Both yellow dots are waiting on manual approval, and they can be approved separately.
- All workflows are run that aren’t set for manual approval (reference) or time-based scheduling (reference)
- In GitHub, if you don’t want to have to wait for manual jobs in order for the status to be green, then you can update settings on GitHub (reference)
- Summary: go to Settings → Branches → Add a new branch protection rule that applies to "" or “something-”
Taking in environment variables with newlines
Section titled “Taking in environment variables with newlines”Sometimes, you’ll have something like a certificate that you want to include as an environment variable. Certificates look roughly like this:
---BEGIN CERTIFICATE---line 1line 2line 3---END CERTIFICATE---You can’t just condense them into a single-line string and expect them to work. Instead, you have to manually join the lines with “n”. However, then your application that receives this environment variable will likely choke, so you need to “undo” the newlines in CircleCI. Here’s an example job of how to do that via “echo -e”:
- run: name: Format APNS certificate and private key to replace "n" with actual newlines command: | echo 'export TF_VAR_APNS_CERTIFICATE=`echo -e $TF_VAR_APNS_CERTIFICATE`' >> $BASH_ENV echo 'export TF_VAR_APNS_PRIVATE_KEY=`echo -e $TF_VAR_APNS_PRIVATE_KEY`' >> $BASH_ENVRunning Python on a Node image
Section titled “Running Python on a Node image”The easy way of running Python on a Node image
Section titled “The easy way of running Python on a Node image”There are two solutions here:
- SUPER EASY: find an image that has Python and Node on Docker Hub, e.g. 3.6-stretch-node from their official Python Dockerfiles
- To quickly check the version of something (e.g. “which version of Node is in that image?”), just make a container on your local machine: docker run -it circleci/python:3.6-stretch-node bash
- node -v
- python3 -V
- To quickly check the version of something (e.g. “which version of Node is in that image?”), just make a container on your local machine: docker run -it circleci/python:3.6-stretch-node bash
- EASY: make an image yourself - you may need to include parts of the CircleCI images (e.g. their extension to Python installs “jq” for parsing JSON data for the AWS CLI and installs Docker for building images). See below for an example Dockerfile.
- You don’t even need to push this to DH if you’re only going to use it locally
Here’s the Dockerfile that I ended up creating:
FROM circleci/python:3.6.1
COPY --from=circleci/node:8.12 /opt/yarn-* /opt/yarnCOPY --from=circleci/node:8.12 /usr/local/bin/node /usr/local/bin/COPY --from=circleci/node:8.12 /usr/local/lib/node_modules /usr/local/lib/node_modulesRUN sudo ln -s /usr/local/lib/node_modules/npm/bin/npm-cli.js /usr/local/bin/npm && \ sudo ln -s /usr/local/lib/node_modules/npm/bin/npx-cli.js /usr/local/bin/npx && \ sudo ln -s /opt/yarn/bin/yarn /usr/local/bin/yarn && \ sudo ln -s /opt/yarn/bin/yarnpkg /usr/local/bin/yarnpkg
CMD ["/bin/sh"]Explanations for the above:
- It’s easier/faster to copy Node than it is to install Python (see installing Python the hard way), which is why I start with the Python image and add Node in.
- I copy /opt/yarn-* so that I don’t have to specify the Yarn version. This means that it gets saved to a folder named “yarn” rather than “yarn-v1.9.4” or whatever it is in circleci/node:8.12.
- The symlinks are to mirror how circleci/node:8.12 operates.
- The reason I sourced a circleci Docker image to begin with is so that I didn’t have to worry about installing JQ or Docker. Originally, I had this configuration, but then Docker wasn’t installed:
FROM nikolaik/python-nodejs:latest
RUN apt update && apt install -y jq
CMD ["/bin/sh"]The hard way of running Python on a Node image
Section titled “The hard way of running Python on a Node image”OH BOY. This took so long to figure out. The overall summary:
- You probably don’t want this; read the easy way to do this.
- I needed Python 3.6, not 3.4.
- The steps to copy into config.yml are below.
- This ends up adding a lot of time to the build process. On my relatively beefy machine, it took 50% of my physical CPU for about 70 seconds just for the Python step. This is only needed when running locally since you can just use the circleci/python:3.6.1 Docker image online and have all of this in an instant (you’d be able to do that locally too if you could cache previous steps; see below for full explanation).
- Eventually, I should be able to just install Python3 (and maybe python3-pip if needed) using “apt”
Here was the scenario I was going for:
- I wanted to deploy a container that I built to AWS
- I wanted to test this locally
Testing locally doesn’t let you run more than one job at a time, so I needed to combine the “build” and “deploy” jobs into a single, mega-job. That was problematic because building requires Node, and deploying requires Python, and those don’t operate nicely across two containers. I figured I would just use the Node Docker image and install Python onto it, but I kept getting a problem where “ensurepip” wasn’t installed:
python3 -V
Section titled “python3 -V”Python 3.4.2
pip3 -V
Section titled “pip3 -V”pip 1.5.6 from /usr/lib/python3/dist-packages (python 3.4)
python3 -m venv venv
Section titled “python3 -m venv venv”Error: Command ’[‘/venv/bin/python3’, ‘-Im’, ‘ensurepip’, ‘—upgrade’, ‘—default-pip’]’ returned non-zero exit status 1
python3 -Im ensurepip
Section titled “python3 -Im ensurepip”/usr/bin/python3: No module named ensurepip
python3
Section titled “python3”>>> help(‘modules’)
(it doesn’t list ensurepip - no idea why though)
I installed the circleci/python:3.6.1 Docker image and everything was set up correctly there, so I hunted down the closest possible Dockerfiles that I could find:
- Python 3.6 for [Debian] jessie
- CircleCI’s extension of Python 3.6.3 (note: this doesn’t actually extend the one above, but it’s close enough)
In the Python 3.6 image, we can see that they wget get-pip.py from some pypa.io. I tried this out myself in Python 3.4, but it didn’t help. I concluded that I needed Python 3.6, which unfortunately isn’t in the main Debian repositories. I found instructions on how to install Python 3.6 from a tar file here. The instructions include running “./configure —enable-optimizations”, which I believe produces an optimized Python build. That’s nice, but the tests took >5 minutes to run, which IMO was unacceptable. I found instructions here on how to skip running the tests. This gave me a final set of steps that I could add to the config.yml:
- run:
name: Install Python3command: | wget https://www.python.org/ftp/python/3.6.3/Python-3.6.3.tgz tar xvf Python-3.6.3.tgz cd Python-3.6.3 ./configure make -j8 sudo make altinstall sudo ln -s python3.6 /usr/local/bin/python3To test this, I just made a container from a Node image, connected to it with ” docker exec -it -u 0 {container ID} /bin/sh”, and ran the individual steps starting with wget and ending in “sudo make altinstall”. It produces /usr/local/bin/python3.6. Running that and typing help(‘modules’) shows that “ensurepip” is installed correctly, which meant that “python3 -m venv venv” will work from this line of their config.yml.
Skipping CI (reference)
Section titled “Skipping CI (reference)”If you don’t want CI to run for any of the commits in an entire push, then add “[skip ci]” or “[ci skip]” anywhere in any commit.
Deploying to AWS ECR (Elastic Container Registry) (reference)
Section titled “Deploying to AWS ECR (Elastic Container Registry) (reference)”These notes are helpful if you want to build a Docker image and push it to ECR.
HiDeoo: It builds & dockerize an app and then push it to ECR and deploy it to ECS Fargate which is your exact use case Adam13531 so you’ll be covered
The final config.yaml that they produce from these instructions is here. That repo also contains other mandatory files like requirements.txt (so that the AWS CLI can be installed) and deploy.sh (which is responsible for putting the container on Fargate).
I specifically do not want to have to commit any Docker-related resources (e.g. Dockerfile or the ECS task definition) from CI. So, for example, the Docker image that we create should be tagged with something like “latest” so that I don’t have to update the task definition.
The steps start with using Terraform to set up a VPC, a role, a cluster, a service, and an ECR repository. I did all of that manually, so I skipped those steps. I’m also not planning on using Terraform. Because of that, I needed to manually add these environment variables in CircleCI (Workflows → Click the ⚙ of the project you want → Build settings → Environment variables):
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
- AWS_DEFAULT_REGION
- AWS_ACCOUNT_ID
- AWS_RESOURCE_NAME_PREFIX
I didn’t use their $FULL_IMAGE_NAME stuff because
I learned quite a bit here for how to choose the executor for something like this. In my case, I need Node/Yarn to be able to even call my “docker:build” script from my package.json, so I would want a base image of something like “circleci/node:8.12” so that I have Node and Yarn. I also need “setupremote_docker ” since it’s for building Docker images in a secure environment. Note that “setup_remote_docker ” is not compatible with “machine” or “macos” executors, so you _have to use Docker.
Because I’m using circleci/node as my Docker image, I don’t need to install the Docker client since they’ve already done that in the image.
CLI and testing locally (reference)
Section titled “CLI and testing locally (reference)”Basics
Section titled “Basics”- Strongly consider whether you really need to test locally to begin with! I ended up spending close to 16 hours just wrestling with local builds and their repercussions. For example, the increased constraints led to this note ballooning like crazy with caveats, but even once I was done getting everything working locally, I needed to massage the config to get it working remotely (which is what took another ~4 hours). Granted, in the future, I could probably avoid a lot of this, but I don’t know if it’s worth it given that the only real reasons to test anything locally are:
- You don’t want to pay $50/month to get off the free tier (although keep in mind, you can always pay for a single month and then drop back down to the free tier (reference)).
- You don’t have the resources to be able to fit in test builds amongst the real builds that you’re doing (i.e. you’re paying for, say, 2 containers at a time, and those 2 containers are almost always in use).
- If you want to test a configuration without burning through all of your monthly minutes, you can clone your repository and test locally. Keep in mind that this does not export environment variables as those are encrypted (reference). You’ll need to do “-e key=value” to test that.
- To obscure this while streaming, you can make a shell script that exports the environment variables (i.e. just a bunch of “export accesskey=secret” lines), then “access_key”. This is not _actual security, it’s just one extra layer to make it a little more difficult to leak secrets.
- Keep in mind that in Bash, there are lots of characters that you have to escape, so it’s best to just surround your variables in single quotes, e.g. “export secret_key=‘}bunch of garbage[]:={’”
- To obscure this while streaming, you can make a shell script that exports the environment variables (i.e. just a bunch of “export accesskey=secret” lines), then “access_key”. This is not _actual security, it’s just one extra layer to make it a little more difficult to leak secrets.
- You cannot use the CLI to run a workflow; you have to run individual jobs. That should be fine this since workflows are just a combination of jobs anyway; you can make a giant job or separate jobs just for testing locally.
- Installation (reference)
- Get the circleci executable (reference)
- You have to create a token for this
- The token gets saved into ~/.circleci/cli.yml
- Note: they tell you to validate your configuration without necessarily telling you to clone a repo, so “circleci config validate” is going to fail since it can’t read the configuration from your home directory by default (although you can specify it manually as an argument). When they say “clone a repo”, they just mean your Git repo that happens to have a .circleci/config.yml. This is why you should be storing your config.yml in your repository rather than in their back-end.
- Running is only done via “circleci local execute”, of which “circleci build” happens to be an alias for. By default, the job name is “build”, but you can override it with “—job JOBNAME”. Note that this _always runs in a container, so you won’t see any changes to your local filesystem.
- Locally, you can’t explore the whole container after CircleCI is done. If you want to be able to do that, I think you may be able to explore the “—volume” option so that the host can store what’s in the container.
- The way you specify volumes follows Docker’s format:
- [14:07] v1cus: It is -v [PATH_ON_YOUR_MACHINE]:[PATH_IN_THE_DOCKER_CONTAINER]
- I never got this to work. I think the issue may be this one, but I’m honestly not sure. The command I tried was
- The way you specify volumes follows Docker’s format:
circleci local execute —job verdaccio_buil
d —branch adam-verdaccio -v “/home/adam/docker_volumes:/home/circleci/botland” and the error I got was “Error: Unable to create directory ‘/home/circleci/botland/packages/verdaccio’“. I just gave up and switched to using “ls” from inside the container.
-
Remotely, you can choose “rerun job with SSH” in the “rerun workflow” dropdown, but this costs monthly minutes.
-
[DEBUGGING TIPS] As a workaround, you can just run “ls” in the container from the config.yml. That’s for chumps though.
- As a BETTER workaround, you can add a “sleep 10000” to the config.yml and then connect to the container:
- Add this step
- As a BETTER workaround, you can add a “sleep 10000” to the config.yml and then connect to the container:
-
run:
name: Testeroni
command: sleep 10000
-
When that step gets hit, do a ”$ docker ps” and look for the container that does not have “circleci build” in it.
-
Connect to it with docker exec -it -u 0 {container ID} /bin/sh
-
“top” or any other built-in command that doesn’t exit would also be fine.
-
Keep in mind that you only get 10 minutes no matter what you do, then you’ll get an error saying “Error: Too long with no output (exceeded 10m0s)“.
-
You can specify which branch you want to build with via “—branch BRANCH_NAME”. This is helpful if your files are not in the master branch, which is what’s assumed by default.
-
Your code is likely checked out via the ”- checkout” command, so any changes you make to versioned assets needs to be pushed to the branch that you’re specifying via “—branch BRANCH_NAME” when running CircleCI.
After all of the above, here’s a sample build command that I use:
circleci build —job verdaccio_build —branch adam-verdaccio
Workspaces
Section titled “Workspaces”Example
Section titled “Example”Here’s an example of saving/reading from a workspace:
terraform_plan: working_directory: ~/botland steps: - persist_to_workspace: root: ~/botland/terraform paths: - .terraform - terraform.tf
terraform_apply: working_directory: ~/botland steps: - checkout - attach_workspace: at: ~/botland/terraform # None of the following is needed if you have attach_workspace above - run: name: Copy workspace folders to correct locations command: | cp workspace/terraform.tf ~/botland/terraform/ cp -r workspace/.terraform ~/botland/terraform/As mentioned in a comment above “run”, you can attach to an existing directory and you’ll get all of the workspace’s files added on top of whatever is already in the existing directory. Also, you can use the tilde as an alias to the home directory and not have to worry; it’s still considered an absolute path (albeit one with an alias).
How I run this locally from Windows (well, a VM in Windows)
Section titled “How I run this locally from Windows (well, a VM in Windows)”-
I set up a Linux VM and SSH into it
-
I use WinSCP to edit config.yml over SFTP
- MAKE SURE NOT TO HAVE CRLF LINE ENDINGS OR YOUR EXECUTABLE SCRIPTS WILL BREAK WITH CRYPTIC ERRORS
-
I make .circleci/secret_env.sh (which I edit over WinSCP as well). The contents need to roughly mirror what’s in the environment variables in production.
- export foo=bar
- export baz=qux
-
I source that secret_env.sh so that the “-e” parameters below will work
-
I use the localcircleci Docker image that I made. For more information, look at this section.
-
Anything with “attach_workspace” that later attempts to use “workspace/” should just drop the “workspace/” part. E.g. below, you would delete the bolded part:
-
attach_workspace:
at: workspace
- run:
name: Load image
command: |
sudo docker load —input **workspace/**docker-image/image.tar
You also have to make sure the working directory is correct, otherwise ./docker-image may not exist.
- I put everything into a single “mega” job for testing since workflows don’t work locally.
- I run the command to build: AWS_ACCESS_KEY_ID -e AWS_ACCOUNT_ID=AWS_DEFAULT_REGION -e AWS_RESOURCE_NAME_PREFIX=AWS_SECRET_ACCESS_KEY -e htpasswd=$htpasswd
- When I’m done, I undo anything from above, e.g. I have to split jobs back into separate jobs/workflows.
localcircleci
Section titled “localcircleci”This is the name of the local Docker image that I built specifically for myself to be able to run CircleCI. There are two major things that this does:
- Set up all of the required programs (Node, Python/PIP, JQ, Docker) from a single image since we have to make a single, “mega” job rather than being able to use workflows
- Set “USER root” so that I don’t have to specify “sudo” all over config.yml, even in some non-obvious places like “yarn docker:*” or “aws ecr get-login”. Being root one way or another is needed to avoid this problem.
To build this Docker image, navigate to packages/verdaccio and run “yarn docker:build:localforcircleci”.
Authenticating to NPM
Section titled “Authenticating to NPM”- Log in locally using ”$ npm adduser —registry=URL”
- Open ~/.npmrc to find the token correpsonding to the user/registry that you want (only take the part after authToken={COPY ALL OF THIS} as shown in the config below).
- Make new environment variables in CircleCI like NPM_REGISTRY_URL and NPM_REGISTRY_TOKEN
- Add this to your config.yml (changing the names/variables of course):
- run: name: Setup Bot Land registry command: | echo "@botland:registry=$BL_REGISTRY_URL" >> ~/.npmrc echo "//$BL_REGISTRY_URL/:_authToken=$BL_REGISTRY_TOKEN" >> ~/.npmrcIntegration with GitHub
Section titled “Integration with GitHub”GitHub introduced the Checks API in May, 2018, so instead of just a simple pass/fail in your build status, you can report richer results, annotate code with detailed information, and kick off reruns—all within the GitHub user interface. This makes it so that you don’t have to juggle between GH & Circle websites (it’s also easier to see the checks in the GH PR directly rather than a list of jobs in Circle).
GitHub’s resource on this: https://blog.github.com/2018-05-07-introducing-checks-api/
CircleCI’s resource on this: https://circleci.com/blog/see-the-status-of-your-circleci-workflows-in-github/
Troubleshooting
Section titled “Troubleshooting”Rerunning a workflow runs from an old commit
Section titled “Rerunning a workflow runs from an old commit”This is probably the expected behavior of CircleCI, but it led to confusion on multiple occasions for me, so I’m writing it down here.
Whenever you run a workflow, you’re running with a branch and a particular commit. For example:
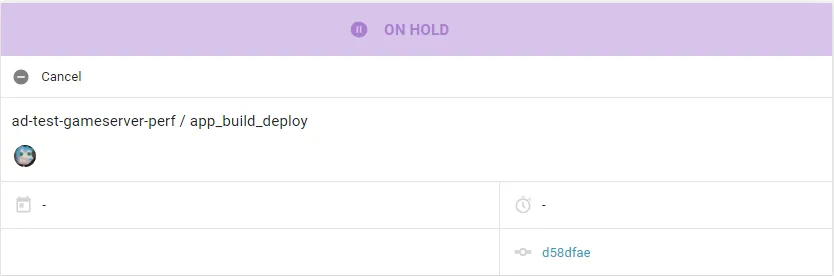
As you can see above, the branch is ad-test-gameserver-perf, and the commit is d58dfae. If that commit does not represent the latest commit, then you will likely have to go to GitHub to schedule the workflow rather than choosing “Rerun from beginning” from the dropdown.
”I approved my job/workflow on CircleCI but it’s still not running anywhere”
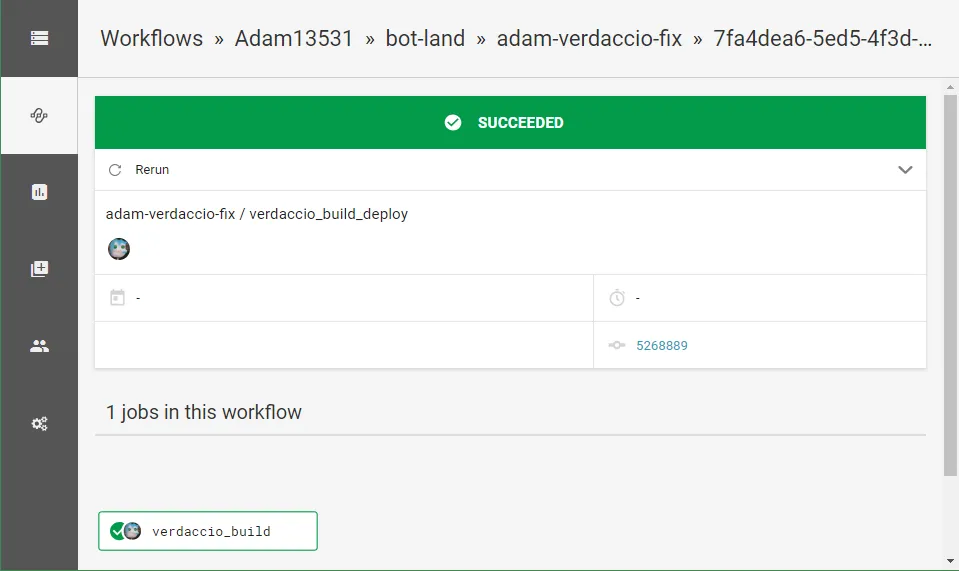
Section titled “”I approved my job/workflow on CircleCI but it’s still not running anywhere””This wasn’t obvious at all, but you can filter a workflow via config.yml so that it only runs on particular branches, e.g.
workflows: version: 2 verdaccio_build_deploy: jobs: - verdaccio_build: # note: this was made before I knew about how "holds" work, so don't just copy/paste this since this should have been named "hold" and verdaccio_build should have been a separate job in this workflow type: approval - verdaccio_deploy: requires: - verdaccio_build filters: branches: only: masterIn that case, you will see a relatively blank UI like this even though you may approve the job:
Catch-all “some command didn’t work” from config.yml
- Is your working directory correct? E.g. I was trying to run “yarn docker:save”, but I was in the wrong directory, so it said “command not found”.
- Note: some commands (like persist_to_workspace, restore_cache and save_cache) do not even allow for a working_directory, so you have to type out the path in those, e.g.
- restore_cache: key: v1-{{ checksum "./packages/verdaccio/requirements.txt" }}- Is this running on CircleCI remotely? If so, you can choose to rerun a job with SSH and connect directly to the container to figure out the state of things as they’re failing.
- Did you accidentally give a named job “type: approval” in a workflow as opposed to just naming it “hold”? If you did, the job doesn’t actually run.
: No such file or directory
This happened to me due to line-ending issues (of all reasons).
I was editing on Windows through FileZilla (so Git wasn’t involved to be able to normalize endings just messed up line endings this entire time, so the whole file ended in CRLF instead of LF, so the #! at the top (#!/usr/bin/env bash) tried finding a path ending in a CR which did not exist.
We encountered a problem adding your identity to CircleCI…
“The identity provided by your VCS service is already associated with a different account. Please try logging in using that account or contact us for further help.”
I don’t know why this shows up exactly, but you can’t just click “Go to app” to fix it since that will be a different session. An incognito window works, but so does clearing site data via F12 → Application → Clear storage → Clear site data. I believe I had to do this on both GitHub and Circleci, but it said circleci was storing 0 bytes as it is.
Your repo is called “project”
Section titled “Your repo is called “project””(…and potentially resides at ~/project)
This is the result of not having a working_directory at the job level (reference).
Permission denied to Docker daemon socket
Section titled “Permission denied to Docker daemon socket”Note: I was trying to run “circleci” locally with a config.yml that tried doing “docker build”.
The error is here:
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post http:///Fvar/Frun/Fdocker.sock/v1.38/build?buildargs=%7B%7D&cachefrom=%5B%5D&cgroupparent=&cpuperiod=0&cpuquota=0&cpusetcpus=&cpusetmems=&cpushares=0&dockerfile=Dockerfile&labels=%7B%7D&memory=0&memswap=0&networkmode=default&rm=1&session=7si3jiwks4jkgtw0ibnbij2x9&shmsize=0&t=botland/Fverdaccio%3A1.0.0&target=&ulimits=null&version=1: dial unix /var/run/docker.sock: connect: permission denied
The resource that finally helped me figure out what to do is this discussion.
Overall conclusion: any “Docker *” commands in the config.yml should have “sudo” before them when testing locally. Make sure to remove “sudo” before pushing.
Workspace issue - “persisted no files”
Section titled “Workspace issue - “persisted no files””I ran into an issue where I had this setup:
- Job 1 runs
- Job 2 is just a manual approval
- Job 3 relies on Job 2
The scenario was that I wanted to run Terraform, so I had “terraform plan” (Job 1), then I could manually approve it (Job 2) to make sure I wouldn’t wipe out my infrastructure, then run “terraform apply” (Job 3).
What I thought was that because I was waiting for Job 1 to finish before approving Job 2 that Job 3 would be able to use the workspace from Job 1. However, without an explicit “requires” directive in config.yml, this will not be the case.
To confirm that this is happening, you will see this in CircleCI’s logs when you run “attach_workspace”:
Downloading workspace layers
Applying workspace layers
7706ba2b-4e37-4510-b547-5d6f85c3cffa - persisted no files
Note: it’s actually okay if some layers don’t have any files; it just means they didn’t save to the workspace. All manual-approval jobs will show that because they don’t do anything other than just require the user to click a button in CircleCI.
Whereas when there are actually files to copy, you’ll see something like this:
Downloading workspace layers
workflows/workspaces/f5e73818-67c3-4ac9-b0c9-0e7657f138e9/0/b2998465-42b1-4f1d-b900-544605130347/0/108.tar.gz - 22 MB
Applying workspace layers
b2998465-42b1-4f1d-b900-544605130347
The solution in this case is to make sure that Job 3 can at least transitively depend on Job 1 as shown below:
workflows: version: 2 terraform: jobs: # Job 1 - terraform_plan
# Job 2 - hold_for_plan: type: approval requires: - terraform_plan
# Job 3 - terraform_apply: requires: - hold_for_planBy setting up your dependencies like this, you should see this graph in CircleCI:

When this wasn’t working, I had this dependency graph:
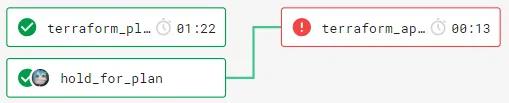
As you can see, terraform-apply does not rely on terraform_plan, so it can’t use the workspace from terraform_plan.
Random CircleCI (or maybe Docker Hub) errors
Section titled “Random CircleCI (or maybe Docker Hub) errors”I got errors like these:
Build-agent version 0.1.1073-1f69f340 (2018-11-20T18:07:03+0000)
Starting container circleci/python:3.6.1
image cache not found on this host, downloading circleci/python:3.6.1
Error response from daemon: unauthorized: authentication required
Starting container circleci/python:3.6.1
image is cached as circleci/python:3.6.1, but refreshing…
Error response from daemon: error parsing HTTP 404 response body: invalid character ‘p’ after top-level value: “404 page not foundn”
- Error response from daemon: linux spec user: unable to find user circleci: no matching entries in passwd file
This turned out to be this issue (which is CircleCI’s fault).
As far as I can tell, something was inaccessible or offline for a fraction of a minute. I just had to rerun the workflow and everything was fine.
Docker caching problem
Section titled “Docker caching problem”On November 26th, 2018, I ran into an issue with “docker build” where it was seemingly using old code or cached layers somehow even though it shouldn’t have been. I had verified that my GitHub had up-to-date code and that the resulting Docker image was being pushed to ECR correctly.
November 26th is also when I was getting random one-off errors from CircleCI for issues that had nothing to do with me and that would be “fixed” after a rerun.
I ended up adding “—no-cache” to the “docker build” command and everything worked fine.
On November 30th, I tried to repro the issue from the 26th by getting rid of “—no-cache” and making superficial changes to a source file. I would then do a “docker pull” and a “docker run” using the latest image from ECR. Everything worked fine, even as I made more changes or reran the same workflow. The only potentially unusual thing is that rerunning the workflow with absolutely no changes didn’t show that every layer was cached. I assume that this is because layer caching is a premium feature, so it’s probably not an issue.
Because everything worked on November 30th, I decided to just leave “—no-cache” out. The way I see it is that I should have proper versioning when I do my “real” deploys, so I would be able to quickly check the version to make sure it’s what I expect rather than having to check individual source files.
Exporting to BASH_ENV didn’t work as expected
Section titled “Exporting to BASH_ENV didn’t work as expected”I ended up writing this out in a step:
echo 'export TF_VAR_FOO="$(cat ./package.json | jq -r ".version")"' >> $BASH_ENVI even printed out the variable right after and it had the contents that I expected. However, the next step failed because the working directory was different, and package.json didn’t exist there. The reason why this failed isn’t immediately obvious—it’s because the line above is adding this to the bash_profile (or bashrc or whatever):
export TF_VAR_FOO="$(cat ./package.json | jq -r ".version")"As you can see, that is not the expanded form that contained the version number that I expected, so it would try finding “./package.json” every time the profile was sourced.
To fix this, write the command in a form that is immediately expanded, e.g.:
echo $(echo "export TF_VAR_FOO=$(cat ./package.json | jq -r ".version")") >> $BASH_ENVThis properly turned into
export TF_VAR_FOO=1.6.3Stuck on “Setup a remote Docker engine”
Section titled “Stuck on “Setup a remote Docker engine””
From what I could find online, this is just a problem with CircleCI, and restarting the job doesn’t necessarily fix anything. I think you just have to wait potentially for many minutes (it seemed to be about 10 when I hit it).